地平线Aux-Think:为什么测试时推理反而让机器人「误入歧途」?丨开发者说
时间:2025-07-15 12:02:35


论文题目:
Aux-Think: 探索数据高效视觉语言导航的推理策略
论文链接:
https://www.php.cn/link/5e0096402339448552f8dff7015d901d
项目主页:
https://www.php.cn/link/680c256fb6e2c27e27a9d268e8379690
视觉语言导航(VLN)中的推理机制研究
在复杂场景下的视觉语言导航在复杂的视觉语言导航任务中,智能体需依据自然语言指令进行实时路径决策。尽管目前的推理机制在多个领域取得了成功,但在VLN(Visual Language Navigation)任务中的应用却相对较少。首次系统性地分析了不同推理策略对这个任务的影响后发现,当前主流的两种推理方法Pre-Think和Post-Think,在测试阶段反而会降低导航性能,导致任务失败。为解决这一问题,我们提出了一种新的框架Aux-Think(辅助思考)。通过结构创新,有效解决了推理带来的负面影响。这种方法能够在不牺牲现有智能体能力的基础上,提高在复杂场景下的路径决策准确性与效率。
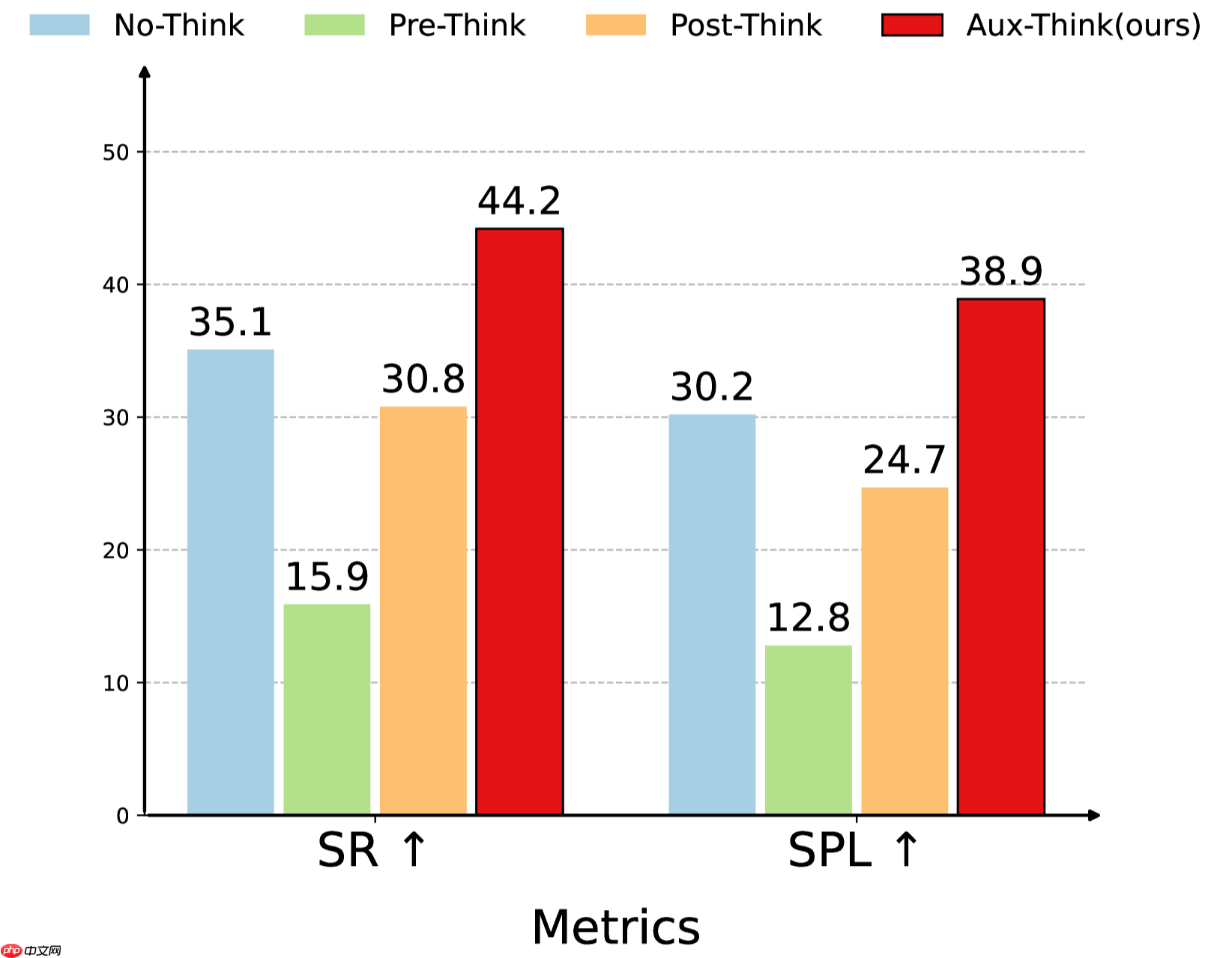
Aux-Think在多种推理策略中表现更优
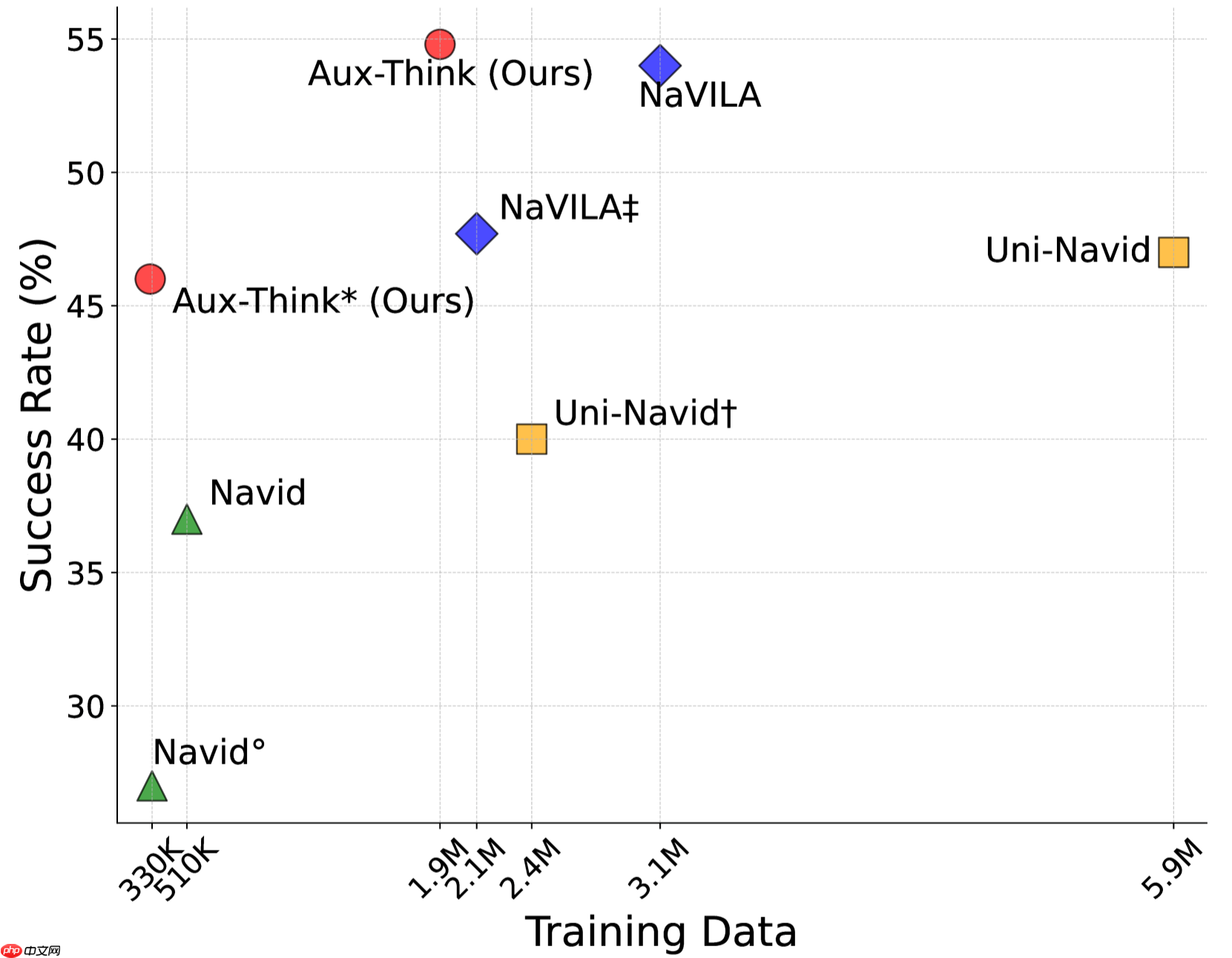
Aux-Think实现了数据效率与成功率的最佳平衡
测试阶段推理存在的难题
想象一个司机在驾驶时不断地回想交通规则和仔细检查道路状况,这样做的确能帮助他们更好地理解和应对周围的环境,但过份依赖这样的方式可能在不熟悉的路段或复杂的路况中导致错误的判断。
在视觉语言导航任务中,推理过程可以被比喻为“复习规则”,而实际操作则对应于“驾驶行为”。虽然推理旨在帮助智能体理解任务要求,但在未覆盖训练状态时,思维链可能会产生幻觉。特别是在不熟悉环境中,过度依赖推理不仅无法提升决策质量,反而会干扰行动、累积误差,最终导致导航失败。这种“推理失效”现象正是Aux-Think所致力于解决的核心问题。

长推理链中的微小错误(标红)也会引发决策偏差
Aux-Think的解决方案
面对诸如复杂场景推理、大规模知识学习等难题,我们提出了一种全新的推理训练框架Aux-Think。其核心理念是,在训练时利用辅助模型协助推理学习,在测试时则完全依赖智能体已有的知识进行决策,从而实现更加高效和精准的推理与决策过程。具体设计包括:在训练阶段引入多个辅助模型,通过它们的学习逐步完善智能体的推理能力;而在测试阶段,直接采用智能体先前掌握的知识进行快速决策,大幅度减少不必要的推理生成步骤,提高系统的运行效率。这一框架不仅适用于复杂任务学习,也能够有效提升AI系统在各种挑战性场景中的表现。
训练阶段:通过引导模型完成推理任务,使其内化推理逻辑。
测试阶段:仅依赖训练阶段习得的知识进行动作预测,跳过推理步骤。
该设计巧妙地减少了测试期间的不确定性和干扰,让智能体能够在执行任务时更加专注,从而提升了其效能和效率。

上图展示了典型的导航挑战:“从房间入口处穿过并到达右侧的拱门,并停在玻璃桌旁”。这三种策略展示了不同的思维过程和表现:Pre-Think模型试图提前规划路径,尽管错误地将距离设定为m,但它未能识别到当前尚未穿越房间;Post-Think模型则在执行任务后才意识到目标未达到,导致错误无法修正;而Aux-Think模型在训练期间学会了推理逻辑并在测试时直接根据观察判断“右转”,最终精准完成导航。
实验结果验证有效性
大量实验证明,Aux-Think在数据利用效率和导航性能方面均优于现有方法。即便使用较少训练数据,Aux-Think也能在多个VLN基准测试中达到单目视觉方法中的最高成功率。通过将推理过程限制在训练阶段,该方法有效缓解了测试阶段的推理幻觉与错误传播,在长距离动态导航任务中展现出更强泛化能力与稳定性。
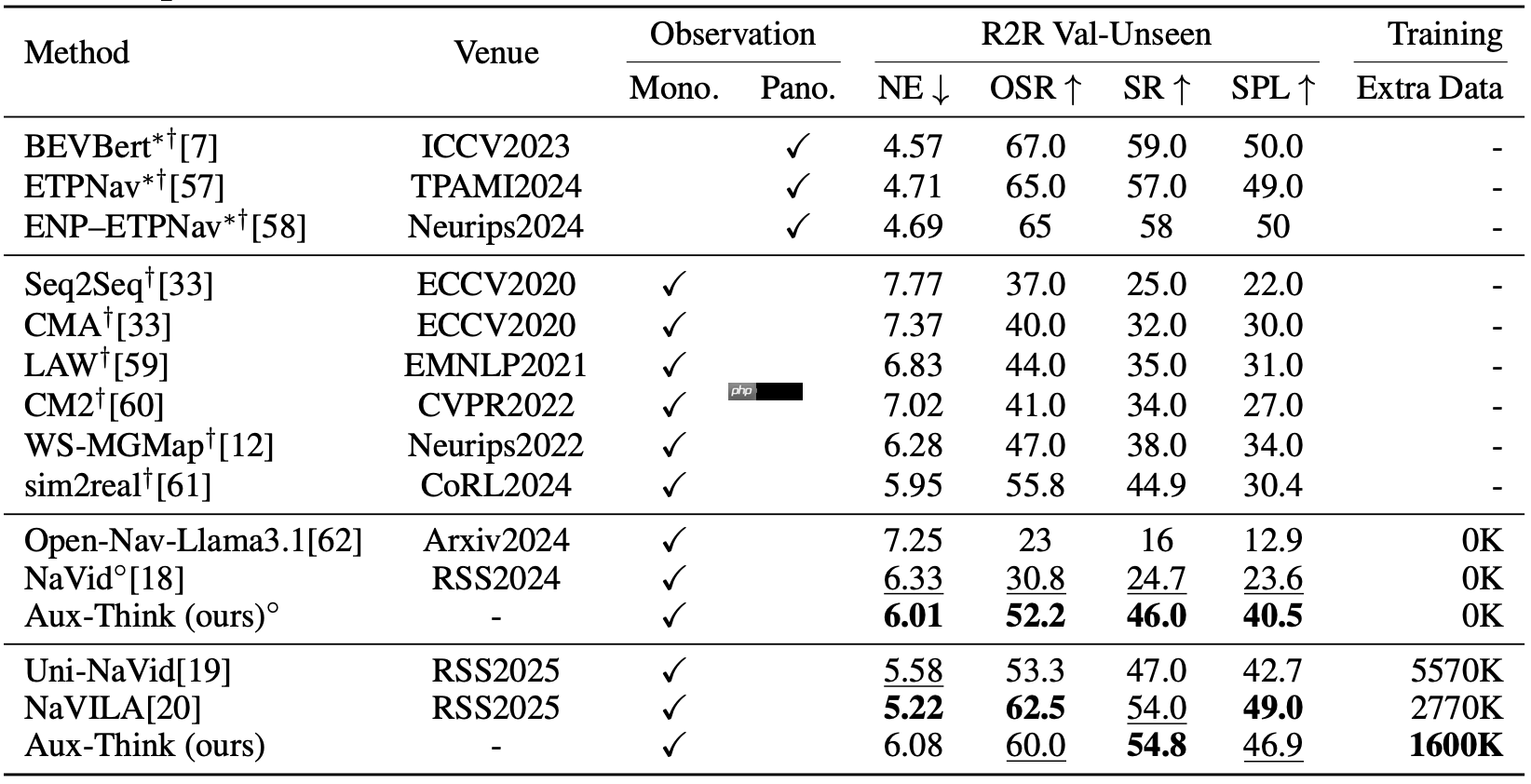
R-CE表明:在视觉语言导航任务中的R验证集(Val-Unseen),Aux-Think使用较少的数据取得了更高的成功率(SR)。
RxR-CE表现突出,表明辅思算法在复杂环境下的成功概率高于R,展现了其强大的泛化能力。
总结与未来方向
Aux-Think为解决测试阶段推理带来的导航问题提供了新思路。通过训练阶段引入推理指导、测试阶段去除推理负担的设计,使智能体能够更专注地执行任务,从而提升导航稳定性与准确性。这一成果为机器人在实际应用中的表现奠定了坚实基础,也为具身智能推理策略的研究提供了重要参考。
以上就是地平线Aux-Think:为什么测试时推理反而让机器人「误入歧途」?丨开发者说的详细内容,更多请关注其它相关文章!
热门推荐
-
 地平线Aux-Think:为什么测试时推理反而让机器人「误入歧途」?丨开发者说论文题目:Aux-Think:探索数据高效视觉语言导航的推理策略论文链接:https://www.php.cn/link/5e9642339448552f8dff
地平线Aux-Think:为什么测试时推理反而让机器人「误入歧途」?丨开发者说论文题目:Aux-Think:探索数据高效视觉语言导航的推理策略论文链接:https://www.php.cn/link/5e9642339448552f8dff -
 外媒称《地平线3》可借鉴《死搁2》 走出美国!GameRant发表了一篇观点文章,提出了对地平线系列第三部正统续作地平线3的大胆构想:或许该系列下一步的发展方向,是像死亡搁浅2一样,走出美国,探索世界其他地区
外媒称《地平线3》可借鉴《死搁2》 走出美国!GameRant发表了一篇观点文章,提出了对地平线系列第三部正统续作地平线3的大胆构想:或许该系列下一步的发展方向,是像死亡搁浅2一样,走出美国,探索世界其他地区 -
 明日地平线英雄排名介绍 明日地平线哪个英雄最厉害游戏是一款充满末日元素的即时对战策略游戏。在游戏中,拥有更多角色的玩家可以构建出更多的阵容组合。因此,如何获得并培养尽可能多的角色成为了一个重要任务
明日地平线英雄排名介绍 明日地平线哪个英雄最厉害游戏是一款充满末日元素的即时对战策略游戏。在游戏中,拥有更多角色的玩家可以构建出更多的阵容组合。因此,如何获得并培养尽可能多的角色成为了一个重要任务 -
 明日地平线兑换码 明日地平线礼包码分享越来越多的游戏开始涉足末日题材,让玩家能穿越到这个危机四伏的世界,体验紧张激烈的生存和对抗。今天要介绍的是明日地平线兑换码,除了使用这些兑换码获取游戏资源外,你还
明日地平线兑换码 明日地平线礼包码分享越来越多的游戏开始涉足末日题材,让玩家能穿越到这个危机四伏的世界,体验紧张激烈的生存和对抗。今天要介绍的是明日地平线兑换码,除了使用这些兑换码获取游戏资源外,你还 -
 明日地平线英雄排名介绍 明日地平线哪个英雄最强在明日地平线这款游戏中,英雄们的力量差距往往能决定战斗的结果。为了帮助大家更好地理解每一位角色的能力,小编特此整理了今日英雄排行榜
明日地平线英雄排名介绍 明日地平线哪个英雄最强在明日地平线这款游戏中,英雄们的力量差距往往能决定战斗的结果。为了帮助大家更好地理解每一位角色的能力,小编特此整理了今日英雄排行榜 -
 小米摄像机为什么会无缘无故休眠 小米摄像机自动休眠解决方法小米摄像机为什么会无缘无故休眠:对于小米的各种产品还是挺多的,同时这些产品也是我们生活中不可或缺的。小米摄像机自动休眠又是怎么一回事呢?小编整理了相关内容介绍,下面一起来看看相关的信息。
小米摄像机为什么会无缘无故休眠 小米摄像机自动休眠解决方法小米摄像机为什么会无缘无故休眠:对于小米的各种产品还是挺多的,同时这些产品也是我们生活中不可或缺的。小米摄像机自动休眠又是怎么一回事呢?小编整理了相关内容介绍,下面一起来看看相关的信息。 -
 大多数下架原因介绍 大多数为什么下架了大多数为什么下架了:对于大多数这款游戏想必很多玩家还是了解的,整个游戏玩起来也是相当有特色的。近日官网给出了大多数下架又是什么问题呢?小编整理了相关内容介绍,下面一起来看看相关的信息。
大多数下架原因介绍 大多数为什么下架了大多数为什么下架了:对于大多数这款游戏想必很多玩家还是了解的,整个游戏玩起来也是相当有特色的。近日官网给出了大多数下架又是什么问题呢?小编整理了相关内容介绍,下面一起来看看相关的信息。 -
 为什么实况照片没声音 iphone实况打开了但是没有声音为什么实况照片没声音:实况照片没声音是因为音效没有开启,如果发现实况照片没有声音,按一下手机左侧的静音键,看看手机目前是否处于静音状态,如果没有静音,查看手机声音是不是被关闭或调至为最小了,所以无法听到实况声音,只需按声音键即可判断。
为什么实况照片没声音 iphone实况打开了但是没有声音为什么实况照片没声音:实况照片没声音是因为音效没有开启,如果发现实况照片没有声音,按一下手机左侧的静音键,看看手机目前是否处于静音状态,如果没有静音,查看手机声音是不是被关闭或调至为最小了,所以无法听到实况声音,只需按声音键即可判断。 -
 tiktok为什么看不了 tiktok看不了解决方法tiktok是外网的抖音名字,外网的跪着和国内完全不一样,审核制度也是不一样的,所以很多网友都是喜欢去外网使用tiktok,但是也有网友发现使用不了,下面就让我们来看看tiktok看不了解决方法。
tiktok为什么看不了 tiktok看不了解决方法tiktok是外网的抖音名字,外网的跪着和国内完全不一样,审核制度也是不一样的,所以很多网友都是喜欢去外网使用tiktok,但是也有网友发现使用不了,下面就让我们来看看tiktok看不了解决方法。 -
 RTS《风暴崛起》新预告 Steam测试已开启发行商THQNordic和开发商SlipgateIronworks公然了RTS游戏《风暴突起》的最新预告
RTS《风暴崛起》新预告 Steam测试已开启发行商THQNordic和开发商SlipgateIronworks公然了RTS游戏《风暴突起》的最新预告 -
 《HTML5》金鱼鱼缸测试网址入口Fishbowl(鱼缸尝试)是另一款来自于微软尝试中央的图形加快尝试,比拟前一条FishIE,Fishbowl的核心在于展现浏览器对于HTML5动画的支持,使用浏
《HTML5》金鱼鱼缸测试网址入口Fishbowl(鱼缸尝试)是另一款来自于微软尝试中央的图形加快尝试,比拟前一条FishIE,Fishbowl的核心在于展现浏览器对于HTML5动画的支持,使用浏 -
 miui14答题测试全部答案2023小米内测答题题库谜底是甚么,此次是必要去探询题目,完成答题就能够获得到miui内测答题的谜底,内里有悉数的题目和谜底,接下来是小编给网友带来的miui14答题尝试悉数谜底-miui14开发版内测谜底2023,好奇的玩家们一起来瞧瞧吧。
miui14答题测试全部答案2023小米内测答题题库谜底是甚么,此次是必要去探询题目,完成答题就能够获得到miui内测答题的谜底,内里有悉数的题目和谜底,接下来是小编给网友带来的miui14答题尝试悉数谜底-miui14开发版内测谜底2023,好奇的玩家们一起来瞧瞧吧。 -
 超星尔雅军事理论章节测试答案超星尔雅军事表面这个课程是好多同砚都必要学习的,这边小编就为网友整理带来了超星尔雅军事表面章节尝试谜底,学习通军事表面章节尝试谜底总结,蕴涵了上海财经大学、同济大学、中北大学的通盘章节尝试谜底,但愿对你有所帮助。
超星尔雅军事理论章节测试答案超星尔雅军事表面这个课程是好多同砚都必要学习的,这边小编就为网友整理带来了超星尔雅军事表面章节尝试谜底,学习通军事表面章节尝试谜底总结,蕴涵了上海财经大学、同济大学、中北大学的通盘章节尝试谜底,但愿对你有所帮助。 -
 巨龙时代:团队副本1号BOSS饰品-「烈焰彩饰」改动后机制二次测试巨龙时代:团队副本1号BOSS饰品-「烈焰彩饰」改动后机制二次测试,副本,饰品,boss,彩饰,护盾
巨龙时代:团队副本1号BOSS饰品-「烈焰彩饰」改动后机制二次测试巨龙时代:团队副本1号BOSS饰品-「烈焰彩饰」改动后机制二次测试,副本,饰品,boss,彩饰,护盾 -
 剧情破案推理游戏下载介绍2025 热门的剧情破案推理游戏推荐最近我发现了一个叫侦探笔记的剧情破案推理手游,它的剧情非常精彩,充满了各种悬疑元素,我非常喜欢。不过我需要下载这个游戏才能玩到
剧情破案推理游戏下载介绍2025 热门的剧情破案推理游戏推荐最近我发现了一个叫侦探笔记的剧情破案推理手游,它的剧情非常精彩,充满了各种悬疑元素,我非常喜欢。不过我需要下载这个游戏才能玩到 -
解析‘如果昨天是明天就好了’的逻辑悖论与假设推理在日常对话中,“如果昨天是明天的话就好了”这句话显得颇为奇特。然而,在深入剖析它的背后隐藏的逻辑与心理动机时,我们不禁会思考:这种假设性的陈述实际上是在探讨一种时
-
热门的剧情破案推理游戏推荐 经典的破案类游戏在注重剧情的烧脑解谜类游戏中,玩家需通过剧情细节理解案件全貌。这些作品以独特的破案方式著称,剧情呈现完美且复杂多变
-
 《汉字找茬王》逐步推理找出凶手攻略详解汉字找茬王逐渐推理找出凶手如何过?汉字找茬王后宫谜团必要小伙伴逐渐推理找出凶手,接下来本站小编给网友整理了汉字找茬王逐渐推理找出凶手方法,快来瞧瞧吧
《汉字找茬王》逐步推理找出凶手攻略详解汉字找茬王逐渐推理找出凶手如何过?汉字找茬王后宫谜团必要小伙伴逐渐推理找出凶手,接下来本站小编给网友整理了汉字找茬王逐渐推理找出凶手方法,快来瞧瞧吧 -
 耐玩的安卓机器人游戏合集 2025有趣的机器一般来说,有机器人元素出现的游戏都是以科幻为主的作品。对于机器人和科幻题材,许多玩家是无比喜爱的。所以说,为了这些喜欢机器人的玩家,小编就特意准备了耐玩的安卓机器
耐玩的安卓机器人游戏合集 2025有趣的机器一般来说,有机器人元素出现的游戏都是以科幻为主的作品。对于机器人和科幻题材,许多玩家是无比喜爱的。所以说,为了这些喜欢机器人的玩家,小编就特意准备了耐玩的安卓机器 -
 《宇宙机器人》2025年7月免费更新追加五个全新关卡TeamAsobi工作室宣布,《宇宙机器人》将于225年7月1日通过免费更新新增五个关卡。此次扩展将使游戏可玩关卡总数突破9大关
《宇宙机器人》2025年7月免费更新追加五个全新关卡TeamAsobi工作室宣布,《宇宙机器人》将于225年7月1日通过免费更新新增五个关卡。此次扩展将使游戏可玩关卡总数突破9大关 -
 赛尔号巅峰之战友情机器人技能介绍 赛尔号巅峰之战友情机器人技能解析今天和各位分享的是赛尔号巅峰之战友情机器人技能介绍,在赛尔号巅峰之战中,友情机器人并非以超高输出或压制性控制著称,它的存在更像是一位战场中的守护者,伴随着主力精灵
赛尔号巅峰之战友情机器人技能介绍 赛尔号巅峰之战友情机器人技能解析今天和各位分享的是赛尔号巅峰之战友情机器人技能介绍,在赛尔号巅峰之战中,友情机器人并非以超高输出或压制性控制著称,它的存在更像是一位战场中的守护者,伴随着主力精灵 -
 一款很老的单机机器人游戏叫什么2025 经典单机机器人游戏有哪些本期为大家带来的是一款很老的单机机器人游戏叫什么225,它们的共同魅力,藏在那台沉重机甲启动时的震颤声中,也藏在每次改装之间权衡火力与机动的抉择里
一款很老的单机机器人游戏叫什么2025 经典单机机器人游戏有哪些本期为大家带来的是一款很老的单机机器人游戏叫什么225,它们的共同魅力,藏在那台沉重机甲启动时的震颤声中,也藏在每次改装之间权衡火力与机动的抉择里 -
 华为开发者大会曝光《王者荣耀》新英雄:孙权即将上线于月日在华为开发者大会上发布的消息显示,王者荣耀合作推出了最新英雄孙权。这标志着双方在游戏领域的进一步合作
华为开发者大会曝光《王者荣耀》新英雄:孙权即将上线于月日在华为开发者大会上发布的消息显示,王者荣耀合作推出了最新英雄孙权。这标志着双方在游戏领域的进一步合作 -
 叙事冒险游戏《混音带》开发者:部分内容取材自身经历开发团队对混音带怀有独特的愿景,旨在将代音乐的独特风格与现代技术结合,创造出独特的故事和沉浸式的体验
叙事冒险游戏《混音带》开发者:部分内容取材自身经历开发团队对混音带怀有独特的愿景,旨在将代音乐的独特风格与现代技术结合,创造出独特的故事和沉浸式的体验 -
 开发者称《塞尔达无双:封印战纪》原为Switch1打造光荣特库摩AAA工作室近日向Famitsu透露,塞尔达无双:灾厄起源最初是作为Switch游戏开发的
开发者称《塞尔达无双:封印战纪》原为Switch1打造光荣特库摩AAA工作室近日向Famitsu透露,塞尔达无双:灾厄起源最初是作为Switch游戏开发的 -
射击大作开发者口出狂言怒喷COD 却惨遭玩家群嘲在最近的夏日游戏节中,尽管有许多新作品展出,但最吸引眼球的无疑是分裂门它之所以广受关注,是由于在发布会中开发者发表了令人震惊的言论,从而引发了激烈的讨论和批评