如何通过豆包AI批量处理文档 豆包AI大规模文档改写方式
时间:2025-08-09 10:14:41
要实现豆包AI批量文档改写,需要构建一个自动化的工作流:首先将文档解析为可被AI理解的文本(使用Python-docx/pdf库和OCR工具),然后通过API调用AI并精细设计prompt(明确目标受众、风格以及需避免的内容)。接着,回写结果并调整其格式;确保质量和一致性是关键:优化prompt、提供改写示例(例如)、设置人工审核机制,并使用脚本统一标点术语。应对技术挑战的策略包括:采用健壮解析库、OCR处理复杂文档、分块改写长文本、添加下文提示,以及设计API限流重试机制以监控成本并减少调用次数;核心技术栈涵盖Python语言、文档库(如python-docx/pdfminer)、OCR工具(如pytesseract或云API)和requests调用AI。整个流程需要兼顾效率、稳定性和可扩展性。

通过豆包AI批量处理文档,特别是进行大规模内容改写的核心在于构建一个自动化工作流。利用API接口,实现从文档内容提取到智能处理(如语言理解、情感分析等),再到结果回写的过程。这不仅仅是简单的复制粘贴,而是智能化的内容再创造,旨在提升效率、统一风格或适应特定发布需求。这样的流程大大提高了信息的处理能力和质量,同时节省了人工成本。

解决方案
为了实现豆包AI大规模文档改写,我建议你构建一个集成了文档处理、AI调用与结果管理的系统。简而言之,这是一个让机器帮你分担工作的解决方案。
首先,你需要解决文档的“输入”问题。无论是Word、PDF还是纯文本,它们都需要被解析成AI可以理解的文本格式。这通常涉及到编程,比如用Python的python-docx库处理.docx文件,或者PyPDFpdfminer.six来提取PDF内容。对于扫描件,OCR(光学字符识别)是必不可少的步骤。这个环节是基础,如果文档解析不准确,后面AI改写得再好也白搭。
立即进入“豆包AI人工智官网入口”;
立即学习“豆包AI人工智能在线问答入口”;

接下来是核心部分:调用豆包AI进行改写。这通常通过其API接口实现。你需要编写脚本将解析出的文本内容作为参数发送给AI。关键是“指令”的艺术,也就是你的Prompt Engineering。你应该明确告诉AI你的改写目标(例如,“将这段技术文档改写成面向非技术人员的科普文章,保持专业性但语言要通俗易懂,避免使用行话”),甚至可以提供几个改写前后的示例,让AI更好地理解你的意图和目标。
收到AI改写后的文本,最后一步是“输出”。这可能意味着将改写后的内容重新插入到新的Word文档、HTML页面或数据库中。在这个阶段,要特别注意保持格式的完整性。如果原始文档有标题、段落、列表等结构,你需要想办法在改写后恢复这些结构,或者至少提供一个可供人工后期编辑的基础。我通常会选择先输出纯文本,然后用一些规则或模板去重建格式,或者直接输出Markdown格式,这样更容易转换为其他格式。
批量改写时,如何确保豆包AI输出内容的质量与风格一致性?
这是一个在批量改写过程中最常见的挑战,同时也是检验AI“自动化”能力的关键点之一。尽管希望人工智能能够完美地解决这个问题,但事实是,在处理多样性和复杂性极高的文档时,这远远超出了单个技术的进步所能达到的程度。在这种情况下,我们需要准备更多的策略和工具来应对这些困难。
我的做法是,首先,精细化你的Prompt。这是不是一句空话呢?不!这是一次真的花时间去打磨的过程。我通常会包含以下几个方面: 明确的改写目标:确定你希望AI润色、扩写、缩写还是改变语境。比如,你是想提高文章的质量还是简化内容? 目标受众:你的AI是为专家、普通大众还是学生设计的?这会影响词汇选择和句子结构。 风格要求:正式、非正式、幽默、严肃、客观还是主观?提供形容词或具体的范例,帮助AI理解你想要传达的信息类型。 禁忌词汇或表达:明确告诉AI哪些词不能用,或者哪些表达方式要避免。这有助于确保生成的内容与你的意图相符。 结构要求:保持原有段落结构还是生成新的标题?如果你希望保留文章的原汁原味,可以保持原有的格式;如果需要创新,不妨尝试生成一个新的结构。通过以上步骤,你可以更有效地利用AI来提高你的写作质量。
其次,采用少样本学习(Few-shot Learning)。先给AI看几个你手动改写过的、符合你期望风格的例子。比如提供三到五对“原文-改写后”的文本,让AI从这些例子中学习你的偏好。这比单纯的文字指令更有效,AI会更“懂”你。
接下来,我们引入了人工审核和迭代机制。确实,完全依赖于机器批量修改的内容质量可能很难达到高标准。通常我会设置一个抽样检查流程,例如每处理文档中,随机抽取进行人工审查。如果发现任何问题,我将根据反馈调整我的提示(Prompt),甚至重新处理之前已经改过的地方。这类似于一种持续优化的循环过程,让AI在实践中不断学习和进步。有时候,我会把AI的输出作为初稿,再由人工进行最后的精修。
最后,通过后处理脚本对文本进行规范化处理是至关重要的一步。虽然AI在许多方面表现出色,但它仍然可能会犯一些小的错误,比如不同的标点符号使用习惯、特定术语的不一致以及数字格式的问题。这时你可以编写简单的脚本来纠正这些问题。例如,你可以使用正则表达式来统一标点符号或创建一个词汇表来替换常见的拼写错误和语法问题。这样不仅能够弥补AI在细节上的不足,还能进一步提升文本的一致性。
豆包AI大规模文档改写中可能遇到的技术挑战与应对策略?
大规模文档改写看似简单,实则充满挑战,需解决的技术问题层出不穷。自动化改写并非一键完成,需要深入理解文本背后的逻辑和结构。
面对常见的文档解析挑战,我们常常感到束手无策。想象一下,你收到的是一个PDF文件,里面可能包含纯文本、嵌入图片或扫描件。而Word文档呢?它不仅有表格、图片和复杂的排版设计,还可能包括各种格式的字体和样式。首先,别被这种复杂性吓倒!解决方案并不是一两步就能搞定的。你需要选择一个健壮的解析库,并且在处理过程中要有针对性的错误处理机制。对于那些复杂的文档,结合OCR(光学字符识别)技术就显得尤为重要了。我的建议是,在预处理阶段将所有文档统一转换为纯文本格式,这样做能极大地提高输入的一致性。这样做的好处在于,AI可以更准确地理解和提取文档中的信息。然而,如果需要保持原有的格式和样式,那么在AI处理完之后,可能还需要通过编程方法来重新“组装”回带有格式的文档模板中。总之,面对这些挑战,我们需要耐心、细心以及不断尝试新的解决方案。通过选择合适的工具、正确的方法和坚持不懈的努力,我们一定能在众多文档解析的困难面前找到突破口!
第二个大挑战是API的限流和稳定性。当你需要处理成千上万份文件时,不可能一次性全部丢给AI模型。在实际操作中,大多数AI服务提供商会设定请求频率和并发量限制。为应对这一问题,你需要精心设计一个稳定高效的请求队列系统和重试机制。例如,我会采用`time.sleep`函数来控制请求间隔时间,或者利用异步编程库如`asyncio`来高效管理多个并发任务。当遇到网络错误或API返回异常时,系统应自动进行重试,并详细记录下失败的文件信息。这类似于泵送水流至各个地方时,需要保持匀速但不致于水流过急导致堵塞。通过这样的设计,保证了系统的稳定性和处理能力。
然后是上下文窗口限制的问题。大多数AI模型都有输入文本长度的限制。如果你有几十页甚至上百页的报告,你不能将整份文件一并交给它来改写。解决办法就是分块处理文档。把长文档拆分成小块,比如按段落或章节,这样可以有效缩短编辑窗口。但是,在每个小块的Prompt中加入前一块或后一块的小部分内容作为上下文参考,或者在完成所有小块的改写后让AI对整个文档进行一次“总结性”的润色,都能帮助保持整体连贯性和逻辑性。
最后,成本控制与效率优化。每一次API调用都是有成本的。大规模改写意味着可能产生不小的费用。你需要监控API的使用量,并且优化你的Prompt,尽量让AI在一次调用中完成尽可能多的任务,减少不必要的往返。同时,并行处理也是提升效率的关键。如果你的服务器资源允许,可以同时启动多个进程或线程来调用API,但前提是要遵守API的限流规定。
构建豆包AI批量文档改写工作流的关键技术栈与工具选择?
要使“豆包AI”文档批量改写流程高效运行,除了依赖先进的AI技术外,还需要一套成熟且适用的工具及技术栈。我认为以下几点至关重要: 高质量的数据输入:丰富的、准确的原始文本数据是基础。 灵活多样的编辑模式:包括自动化的语法检查、错别字修正等。 强大的自然语言处理模型:能够理解并生成不同领域的专业术语和表达。 用户友好界面:方便操作,易于进行管理和监控。 安全性与合规性措施:确保数据安全,遵守相关法律法规。
操作系统:Windows是首选。 原因在于其稳定性和兼容性极佳。无论是日常办公还是专业计算,都能轻松应对。此外,它还支持多种编程语言如C++、Java和Python等,使得跨平台开发更加方便。
文档解析与转换库: python-docx: 处理.docx(Word)文件,可以读取段落、表格内容,并且能够创建新的.docx文件并写入内容。PyPDF/ pdfminer.six: 用于从PDF文件中提取文本。如果PDF是扫描件,你还需要OCR库。Pillow / OpenCV + pytesseract: 当遇到图片格式的文本(如扫描件)时,Pillow或OpenCV进行图像处理,pytesseract是Tesseract OCR引擎的Python封装,能将图片中的文字识别出来。当然,如果你预算充足,直接使用云服务商(例如阿里云、腾讯云、百度AI开放平台)提供的OCR API会更加省心,识别效果也通常更好。BeautifulSoup / lxml: 如果你的文档来源是HTML或XML,这些库可以高效地解析结构化数据。
调用AI服务接口:使用requests:这是Python中最常用的HTTP库,用于向豆包AI API发送请求并接收响应。你需要熟悉HTTP请求方法(如POST)、请求头(尤其是认证信息)和请求体(包括你的Prompt和文本数据)。官方SDK(如有):如果豆包AI有官方的Python SDK,它会封装底层的HTTP请求细节,让你调用更方便。
工作流编排与并发处理:对于规模不大的任务,直接编写Python脚本是有效的。通过for循环处理文件,并结合time.sleep进行简单的限流管理,可以很好地应对小规模的文档改写需求。如果涉及更大范围的工作量或者需要更高效、稳定的处理流程,推荐使用第三方库来实现并发处理。例如,`concurrent.futures`模块提供了`ThreadPoolExecutor`和`ProcessPoolExecutor`两种方式,通过这些工具可以有效地利用多线程或多进程技术加速文档改写工作。对于大规模的文档处理任务,为了确保数据的一致性和容错能力,引入消息队列系统是一个明智的选择。RabbitMQ或Apache Kafka等产品提供了可靠的消息传输机制,使得文档改写的各个步骤可以解耦、同时进行而不相互干扰,从而实现削峰填谷的效果,并提高系统的扩展性。此外,如果你的工作流非常复杂,包含多个步骤的依赖关系和复杂的调度逻辑,那么使用工作流引擎(Workflow Engine)会是一个极佳的选择。Apache Airflow和Prefect等工具能够帮助你定义、管理和监控整个工作流程,确保任务的准确执行以及高效协作。
数据存储与管理:使用本地文件系统:最简单直接的方式,文档直接保存在本地硬盘上。借助云存储:例如阿里云OSS和腾讯云COS,适用于大规模文件的存储和共享,并且能够轻松集成到云端AI服务中。处理数据时考虑元数据:如果你需要管理文档的元信息(包括原始文件名、改写状态和版本信息),推荐使用关系型数据库(如MySQL或PostgreSQL)或NoSQL数据库(例如MongoDB)。这样可以更好地支持复杂的查询需求。
错误处理与日志记录: try-except块: 这是Python中处理异常的基础,确保程序在遇到错误时不会崩溃。logging模块: Python标准库中的日志模块,用于记录程序的运行状态、警告和错误信息。详细的日志对于排查批量处理中出现的问题至关重要。
构建这样一个工作流并非易事,它要求对文档处理、AI接口、并发编程以及系统稳定性有深入的理解。然而,一旦实现,它将显著提升你的工作效率。
以上就是如何通过豆包AI批量处理文档 豆包AI大规模文档改写方式的详细内容,更多请关注其它相关文章!
热门推荐
-
 华为手机上传到中转站怎么关闭 华为手机如何关闭上传到中转站华为手机如何关闭上传到中转站:对于华为手机不少用户都在使用啦,当然这可手机功能也是非常强大的。对于这款世界如何关闭上传到中转站呢?小编为玩家整理了相关内容,下面一起来看看相关的信息。
华为手机上传到中转站怎么关闭 华为手机如何关闭上传到中转站华为手机如何关闭上传到中转站:对于华为手机不少用户都在使用啦,当然这可手机功能也是非常强大的。对于这款世界如何关闭上传到中转站呢?小编为玩家整理了相关内容,下面一起来看看相关的信息。 -
 三国志11威力加强版庙和遗迹如何触发 三国志11庙和遗迹坐标位置机制详解三国志11威力加强版庙和遗迹如何触发:在三国志11游戏中很多玩法还是挺多的,对于游戏中庙和遗迹我们又该如何触发呢?想必不少玩家还是不了解的,小编整理了三国志11庙和遗迹机制详解,下面一起来看看相关的信息。
三国志11威力加强版庙和遗迹如何触发 三国志11庙和遗迹坐标位置机制详解三国志11威力加强版庙和遗迹如何触发:在三国志11游戏中很多玩法还是挺多的,对于游戏中庙和遗迹我们又该如何触发呢?想必不少玩家还是不了解的,小编整理了三国志11庙和遗迹机制详解,下面一起来看看相关的信息。 -
 学习通如何查看学号工号_学习通查看学号工号方法介绍学习通查看学号工号方法介绍:对于学习通这款软件功能还是挺多的,在这款软件想要查询工号又该如何搞呢?这也是很多用户不了解的,在这里为用户整理了学习通查看工号学号方法介绍,下面一起来看看相关的信息。
学习通如何查看学号工号_学习通查看学号工号方法介绍学习通查看学号工号方法介绍:对于学习通这款软件功能还是挺多的,在这款软件想要查询工号又该如何搞呢?这也是很多用户不了解的,在这里为用户整理了学习通查看工号学号方法介绍,下面一起来看看相关的信息。 -
 学习通如何添加好友_学习通添加好友方法教程学习通添加好友方法教程:在学习通这款软件功能还是挺多的,对于这款软件想和别人聊天又该如何搞呢?这也是很多玩家不了解的,小编整理了学习通添加好友方法介绍,下面一起来看看相关的信息。
学习通如何添加好友_学习通添加好友方法教程学习通添加好友方法教程:在学习通这款软件功能还是挺多的,对于这款软件想和别人聊天又该如何搞呢?这也是很多玩家不了解的,小编整理了学习通添加好友方法介绍,下面一起来看看相关的信息。 -
 uc浏览器收藏如何设置密码_uc浏览器隐私收藏设置方法介绍uc浏览器收藏如何设置密码:对于uc浏览器这款软件想必很多用户都在使用,当然在这款软件隐私收藏如何加密呢?想必很多玩家还是不了解的,小编整理了相关内容介绍,下面一起来看看相关的信息。
uc浏览器收藏如何设置密码_uc浏览器隐私收藏设置方法介绍uc浏览器收藏如何设置密码:对于uc浏览器这款软件想必很多用户都在使用,当然在这款软件隐私收藏如何加密呢?想必很多玩家还是不了解的,小编整理了相关内容介绍,下面一起来看看相关的信息。 -
 三星 Galaxy Z Flip7 手机通过“弯曲测试”,但内屏易刮花近日YouTube视频博主JerryRigEverything对三星GalaxyZFlip进行了测试,结果显示该机具有出色的耐用性
三星 Galaxy Z Flip7 手机通过“弯曲测试”,但内屏易刮花近日YouTube视频博主JerryRigEverything对三星GalaxyZFlip进行了测试,结果显示该机具有出色的耐用性 -
 魅族 22 系列两款新机通过工信部入网,包含“AI 小屏旗舰”感谢xiayx网友尘缘理还乱、百里屠苏哈的线索投递!xiayx8月12日消息,今天有两款魅族5G手机新品通过了工信部入网认证获公示,型号分别为M582V、M582
魅族 22 系列两款新机通过工信部入网,包含“AI 小屏旗舰”感谢xiayx网友尘缘理还乱、百里屠苏哈的线索投递!xiayx8月12日消息,今天有两款魅族5G手机新品通过了工信部入网认证获公示,型号分别为M582V、M582 -
 如何通过豆包AI批量处理文档 豆包AI大规模文档改写方式要实现豆包AI批量文档改写,需要构建一个自动化的工作流:首先将文档解析为可被AI理解的文本(使用Python-docx/pdf库和OCR工具),然后通过API调用
如何通过豆包AI批量处理文档 豆包AI大规模文档改写方式要实现豆包AI批量文档改写,需要构建一个自动化的工作流:首先将文档解析为可被AI理解的文本(使用Python-docx/pdf库和OCR工具),然后通过API调用 -
 painter怎么长按调出吸管-painter怎样通过长按调出吸管掌握Painter的多功能技巧不仅能快速完成绘图任务,还可以提高工作效率。长按调出吸管功能是不可或缺的小工具,帮助你精准复制和调整色彩
painter怎么长按调出吸管-painter怎样通过长按调出吸管掌握Painter的多功能技巧不仅能快速完成绘图任务,还可以提高工作效率。长按调出吸管功能是不可或缺的小工具,帮助你精准复制和调整色彩 -
 如何通过豆包AI批量生成产品描述 豆包AI电商文案高效创建要实现豆包AI批量生成产品描述,以下是简化后的步骤:整理结构化数据:首先需要将产品信息整理成可使用的格式,比如CSV表格
如何通过豆包AI批量生成产品描述 豆包AI电商文案高效创建要实现豆包AI批量生成产品描述,以下是简化后的步骤:整理结构化数据:首先需要将产品信息整理成可使用的格式,比如CSV表格 -
 如何用豆包AI写程序 豆包AI编程功能指南豆包AI利用其强大的功能为开发者提供了一站式的编程辅助服务。首先,它会根据你的需求明确描述并指定编程语言,然后你必须指明具体逻辑流程或参考现有代码片段
如何用豆包AI写程序 豆包AI编程功能指南豆包AI利用其强大的功能为开发者提供了一站式的编程辅助服务。首先,它会根据你的需求明确描述并指定编程语言,然后你必须指明具体逻辑流程或参考现有代码片段 -
 如何用豆包AI制定西安3天2夜美食之旅?预算控制与景点推荐规划西安美食之旅的关键在于明确你的预算、口味喜好以及想要探索的景点。首先,设定一个合理的预算范围(例如:),然后列出你期待品尝的美食(如肉夹馍、羊肉泡馍和凉皮)以
如何用豆包AI制定西安3天2夜美食之旅?预算控制与景点推荐规划西安美食之旅的关键在于明确你的预算、口味喜好以及想要探索的景点。首先,设定一个合理的预算范围(例如:),然后列出你期待品尝的美食(如肉夹馍、羊肉泡馍和凉皮)以 -
 豆包上线AI播客功能,比扣子空间速度更快。刚刚,豆包电脑版和网页版正式推出了“ai播客”功能。网址:doubao.com只需点击“A|播客”并上传PDF文件或输入网页链接,即可生成双人对话形式的播客内容
豆包上线AI播客功能,比扣子空间速度更快。刚刚,豆包电脑版和网页版正式推出了“ai播客”功能。网址:doubao.com只需点击“A|播客”并上传PDF文件或输入网页链接,即可生成双人对话形式的播客内容 -
 豆包AI详细功能解析 豆包AI以图生图全流程介绍豆包AI的“以图生图”功能通过上传图片并结合提示词与参数调整实现图像再创作。其核心亮点包括多模态交互、智能对话和文生图功能
豆包AI详细功能解析 豆包AI以图生图全流程介绍豆包AI的“以图生图”功能通过上传图片并结合提示词与参数调整实现图像再创作。其核心亮点包括多模态交互、智能对话和文生图功能 -
 painter怎么批量分享笔刷-painter如何进行笔刷批量分享一、准备笔刷准备好了吗?立即创建一个专门的笔刷文件夹,便于管理和访问你的作品!二、导出笔刷-打开painter软件
painter怎么批量分享笔刷-painter如何进行笔刷批量分享一、准备笔刷准备好了吗?立即创建一个专门的笔刷文件夹,便于管理和访问你的作品!二、导出笔刷-打开painter软件 -
 自媒体如何用AI工具批量生成内容?核心操作教程新的自媒体使用AI工具批量生成内容的核心在于将AI视为高效“思考伙伴”和“初稿生成器”,而非完全替代人类
自媒体如何用AI工具批量生成内容?核心操作教程新的自媒体使用AI工具批量生成内容的核心在于将AI视为高效“思考伙伴”和“初稿生成器”,而非完全替代人类 -
 diskgenius怎么批量格式化USB磁盘?-diskgenius批量格式化USB磁盘的方法DiskGenius是专业级数据恢复工具,如何用它批量格式化USB闪存盘?详细教程在这里!diskgenius怎么批量格式化USB磁盘?-打开DiskGenius
diskgenius怎么批量格式化USB磁盘?-diskgenius批量格式化USB磁盘的方法DiskGenius是专业级数据恢复工具,如何用它批量格式化USB闪存盘?详细教程在这里!diskgenius怎么批量格式化USB磁盘?-打开DiskGenius -
 微信鸿蒙版本不好用如何解决-微信鸿蒙版本不好用怎么处理在使用微信鸿蒙版本时,不少用户反映遇到了一些问题,感觉不太好用。别担心,下面为您详细介绍解决办法。检查网络连接确保您的设备已成功连接到稳定的网络。不稳定的网络可能导致微信加载缓慢、消息发送失败等问题。您可以尝试切换网络,比如从wi-fi切换到移动数据,或者反之
微信鸿蒙版本不好用如何解决-微信鸿蒙版本不好用怎么处理在使用微信鸿蒙版本时,不少用户反映遇到了一些问题,感觉不太好用。别担心,下面为您详细介绍解决办法。检查网络连接确保您的设备已成功连接到稳定的网络。不稳定的网络可能导致微信加载缓慢、消息发送失败等问题。您可以尝试切换网络,比如从wi-fi切换到移动数据,或者反之 -
 vivo手机进水如何处理-vivo手机进水后的正确处理方法当vivo手机不幸进水,不要惊慌,以下是一些正确的处理方法,能最大程度减少损失。首先,一旦发现手机进水,应立即关机
vivo手机进水如何处理-vivo手机进水后的正确处理方法当vivo手机不幸进水,不要惊慌,以下是一些正确的处理方法,能最大程度减少损失。首先,一旦发现手机进水,应立即关机 -
 如何用豆包AI自动生成正则表达式 文本处理效率翻倍指南了解豆包AI如何帮你生成正则表达式?详细描述:提供更具体的信息以获得更高的准确度,如域名和用户名的格式细节能增强匹配精度
如何用豆包AI自动生成正则表达式 文本处理效率翻倍指南了解豆包AI如何帮你生成正则表达式?详细描述:提供更具体的信息以获得更高的准确度,如域名和用户名的格式细节能增强匹配精度 -
 DeepSeek AI能不能多窗口操作 DeepSeek AI同时处理多个任务的方法在日常使用人工智能工具时,用户常常希望能够同时进行多项操作或处理多个任务,以提升工作效率。对于DeepSeekAI而言,无论是通过其在线服务平台,还是通过其开放的
DeepSeek AI能不能多窗口操作 DeepSeek AI同时处理多个任务的方法在日常使用人工智能工具时,用户常常希望能够同时进行多项操作或处理多个任务,以提升工作效率。对于DeepSeekAI而言,无论是通过其在线服务平台,还是通过其开放的 -
 deepl翻译如何翻译pdf文档-deepl翻译怎样去翻译pdf文档deepL是一个强大且多语言的文本翻译工具;许多人期待它可以轻松翻译PDF文件。以下是详细步骤!首先,你需要打开deepl的官方网站
deepl翻译如何翻译pdf文档-deepl翻译怎样去翻译pdf文档deepL是一个强大且多语言的文本翻译工具;许多人期待它可以轻松翻译PDF文件。以下是详细步骤!首先,你需要打开deepl的官方网站 -
 如何取消腾讯文档的编辑权限及关闭相机权限详细指南腾讯文档是一个极佳的在线协作平台,能显著提升文件的共享和编辑效率。不过,在实际操作时难免会遇到如需关闭相机权限的情况
如何取消腾讯文档的编辑权限及关闭相机权限详细指南腾讯文档是一个极佳的在线协作平台,能显著提升文件的共享和编辑效率。不过,在实际操作时难免会遇到如需关闭相机权限的情况 -
 百度网盘AI大赛:文档图像摩尔纹消除第二名方案在百度网盘AI大赛中,我们的团队成功解决了图像摩尔纹消除的问题。通过改进的多尺度卷积神经网络(IDR网络),我们取得了在A榜上的第一和在B榜上的第二名的成绩
百度网盘AI大赛:文档图像摩尔纹消除第二名方案在百度网盘AI大赛中,我们的团队成功解决了图像摩尔纹消除的问题。通过改进的多尺度卷积神经网络(IDR网络),我们取得了在A榜上的第一和在B榜上的第二名的成绩 -
 豆包AI怎样生成Markdown文档?技术文章排版自动化豆包AI能够自动生成标准Markdown格式的文本,只需在提问时明确具体要求即可。以下是详细的步骤和注意事项:请求Markdown输出:在指令中明确说明需要以Ma
豆包AI怎样生成Markdown文档?技术文章排版自动化豆包AI能够自动生成标准Markdown格式的文本,只需在提问时明确具体要求即可。以下是详细的步骤和注意事项:请求Markdown输出:在指令中明确说明需要以Ma -
 月底再见 《巫火》下一款大规模更新发布日期公布TheAstronauts公布了巫火下一个“最大规模”更新“韦伯格雷夫”(Webgrave)的发布日期
月底再见 《巫火》下一款大规模更新发布日期公布TheAstronauts公布了巫火下一个“最大规模”更新“韦伯格雷夫”(Webgrave)的发布日期 -
 大规模和超大规模集成电路是第几代大规模和超大规模集成电路是第四代。大规模集成电路通常指含逻辑门数为100门~9999门,在一个芯片上集合有1000个以上电子元件的集成电路。超大规模集成电路是一种将大量晶体管组合到单一芯片的集成电路,其集成度大于大规模集成电路。
大规模和超大规模集成电路是第几代大规模和超大规模集成电路是第四代。大规模集成电路通常指含逻辑门数为100门~9999门,在一个芯片上集合有1000个以上电子元件的集成电路。超大规模集成电路是一种将大量晶体管组合到单一芯片的集成电路,其集成度大于大规模集成电路。 -
 大麦app怎么设置支付方式大麦是一款非常好用的购票软件,在软件中有很多不同的方式,在这里就有用户好奇了怎么设置支付方式呢?现在就来看一下小编带来的设置支付方式的方法吧
大麦app怎么设置支付方式大麦是一款非常好用的购票软件,在软件中有很多不同的方式,在这里就有用户好奇了怎么设置支付方式呢?现在就来看一下小编带来的设置支付方式的方法吧 -
 cod19小黑屋自查方式在cod19的嬉戏过程中有的人会发现显明自个家的网络没有问题,加速器也挂着的,能够是般配游戏的ping值不断都是在2多,并且般配的队友和敌手翻来覆去都是那几个人
cod19小黑屋自查方式在cod19的嬉戏过程中有的人会发现显明自个家的网络没有问题,加速器也挂着的,能够是般配游戏的ping值不断都是在2多,并且般配的队友和敌手翻来覆去都是那几个人 -
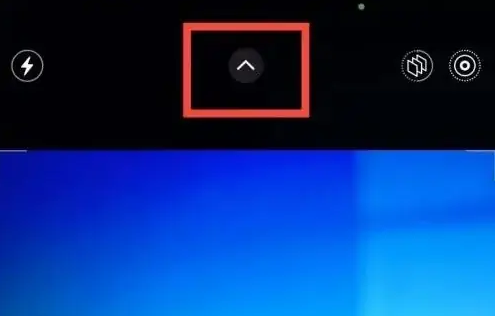 苹果15怎么拍月亮-iPhone拍月亮正确方式苹果15系列手机拥有强大的摄影能力,可以帮助用户拍摄出令人惊艳的月亮照片,但如果你想要拍摄一个清晰的月亮照片的话,那小编今天分享的教程文章,你们可要好好学习下了。苹果15怎么拍月亮第一步、在苹果15相机界面点击上方红框内的图标,进入相机设置界面。第二步、在相机设置中选择红框内的图标,进入曝光率设置界面。第三步、左滑曝光率刻标,将曝光率调整到-2.0。第四步、选择红框内的5x选项,放大5倍,对准月亮
苹果15怎么拍月亮-iPhone拍月亮正确方式苹果15系列手机拥有强大的摄影能力,可以帮助用户拍摄出令人惊艳的月亮照片,但如果你想要拍摄一个清晰的月亮照片的话,那小编今天分享的教程文章,你们可要好好学习下了。苹果15怎么拍月亮第一步、在苹果15相机界面点击上方红框内的图标,进入相机设置界面。第二步、在相机设置中选择红框内的图标,进入曝光率设置界面。第三步、左滑曝光率刻标,将曝光率调整到-2.0。第四步、选择红框内的5x选项,放大5倍,对准月亮 -
 乐播投屏破解版无限刷:多种方式的投屏功能哟乐播投屏破解版无限刷是一款能帮助网友们迅速将雅观资本进行大屏投放功能的手机软件,各式影戏、短视频等等的音/视频资本支持网友们投屏播放哟,更能让网友们一键直接到
乐播投屏破解版无限刷:多种方式的投屏功能哟乐播投屏破解版无限刷是一款能帮助网友们迅速将雅观资本进行大屏投放功能的手机软件,各式影戏、短视频等等的音/视频资本支持网友们投屏播放哟,更能让网友们一键直接到 -
 拳皇97怎么放大招摇杆 摇杆大招出招方式介绍拳皇97出每个角色都有奇特的大招,必要使用轻拳、重拳、轻脚和重脚协作对象键才能够放出来,就例如草剃京按→+B能够放出大招外式·轰斧阳,按&
拳皇97怎么放大招摇杆 摇杆大招出招方式介绍拳皇97出每个角色都有奇特的大招,必要使用轻拳、重拳、轻脚和重脚协作对象键才能够放出来,就例如草剃京按→+B能够放出大招外式·轰斧阳,按&