【AI达人特训营第三期】:PaddleSeg助力自动驾驶场景分割
时间:2025-07-30 13:30:59
本文介绍使用PaddleSeg工具处理基于ADE数据集场景解析的过程。首先,解压相关软件及数据集,并加载并预处理它们。采用GCnet模型,其简化注意力机制高效且具有竞争力。此外,还提到了KNet等其他算法以及两种分割方式的优缺点。在训练后,GCnet表现出比Upernet更好的mIoU、耗时和模型大小。最后,分享了调参等经验。

一、项目背景介绍
ADE20K数据集来源
场景解析基准测试:从理论到实践场景解析是将图像分割并解析为与语义类别相关联的不同图像区域,例如天空、道路、人和床。MIT Scene Parsing Benchmark (SceneParse 为这种复杂任务提供了一个标准的训练和评估平台。本次基准测试的数据集来自ADE Dataset,该数据集中包含超过以场景为中心的图像,并且对象和对象部分进行了详尽注释。具体来说,基准测试分为三个部分:用于训练,用于验证,以及另外一批留作测试用。共有语义类别供评估,包括天空、道路、草地、人和车、床等离散对象。这个场景解析基准测试不仅提供了挑战性的任务要求,还捕捉了图像中自然分布的对象类型。请注意,图像中的对象分布并不均匀,这与现实世界中更常见的情况相符。
对于每张图像,分割算法生成一个语义分割掩码,预测像素的语义类别。其性能由像素精度平均值及所有语义类别的平均交并比(IoU)决定。
我们的基准集已与ILSVRC'赛中的多个任务和COCO挑战结合,包括Scene Parsing Challenge Places Challenge 您可以访问场景解析的演示来了解细节。此外,我们还公开了预训练模型和相应代码。
二、准备工作
2.1、使用paddleseg配置文件开发
参考:20分钟快速上手PaddleSeg
也可参考官方aistudio:10分钟上手PaddleSeg In [1]
# 这里准备好了paddleseg套件,直接解压即可!unzip -oq /home/aistudio/data/data201976/PaddleSeg.zip -d /home/aistudio/work/登录后复制
2.2、解压数据集
In [2]
!unzip -oq /home/aistudio/data/data26423/ade20k.zip -d /home/aistudio/work/dataset/登录后复制
2.3、加载数据集
得益于peddseg的完美封装,我们能在低代码环境中迅速便捷地进行数据加载、模型训练及验证工作。只需调整相应的配置文件即可完成这些操作。
数据集的加载和预处理在/home/aistudio/work/PaddleSeg/configs/base/ade20k.yml
三、模型训练
3.1、模型和backbone的选取
这里选用的模型是GCnet
这张图片中各个像素点间的关系,特别是长距离像素点间的互动对各种视觉任务至关重要。这种关系可以通过传统的堆叠卷积层(Stacked Convolutions)来实现,但效率通常不高。Non-local网络采用了自注意力机制(Self-Attention Mechanism),有效地解决了这个问题。然而,对于图像而言,作者发现每个像素点的基本全局特征图是相似的,如图示,其中红色标记的是我们要计算的目标点。基于这一点,我们就不需要为每个点单独计算其全局特征图了。因此,作者提出了一种比Non-local网络效果更好的但计算量较小的简化注意力机制模块(Simplified Attention Mechanism)。这种简化的方法虽然在某些方面略逊于非局部网络,但在计算效率上有了显著提升,并且仍然可以达到良好的性能表现。简化的注意力机制通过共享部分特征并进行多尺度融合,大大减少了模型的参数和内存需求,从而提高了模型的可训练性和鲁棒性。

图1 non-local方法计算的红色点的注意力特征图
非局部计算方法有多种,例如高斯、嵌入式高斯、点积和拼接等。基于此,Graph Convolutional Network (GCNet) 则采用了嵌入式高斯的方法,这也是常见使用的策略。该模块的具体实现细节如图示。从图中可以清晰看到,GCNet模块是对简化版的非局部模块和SE(Self-Attention)机制进行结合的结果。例如,非局部计算方法将输入图节点间的关系通过一系列操作映射到一个固定大小的空间上,并利用空间距离来传递信息,这在图神经网络处理任务中具有重要作用。而嵌入式高斯则是通过构建一个图的向量表示空间,使各节点在其中的位置分布能够反映其非局部属性。这种方法不仅增强了模型对复杂数据的建模能力,还显著提升了模型的泛化能力和性能。简单来说,GCNet是基于非局部计算方法的一个重要组成部分,它结合了嵌入式高斯和自注意力机制的优势,从而在图像处理、推荐系统等多个领域取得了卓越的表现。
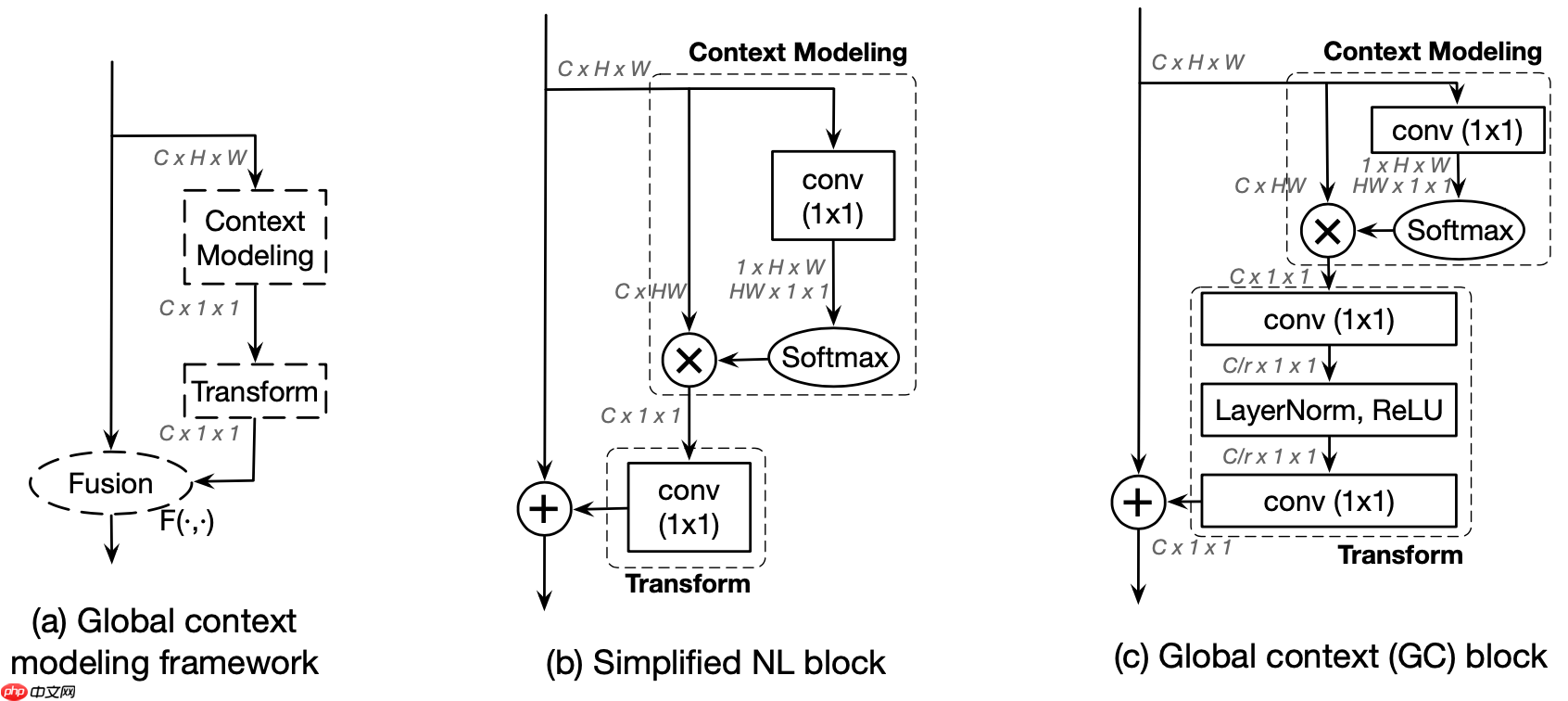
图2 GCNet模块实现细节示意图
详细模型信息可前往/home/aistudio/work/PaddleSeg/models/gcnet.py查看代码细节
配置文件为/home/aistudio/work/PaddleSeg/configs/gcnet/gcnet_resnet50_os8_voc12aug_512x512_40k.yml
backbone为经典的resnet50_vd
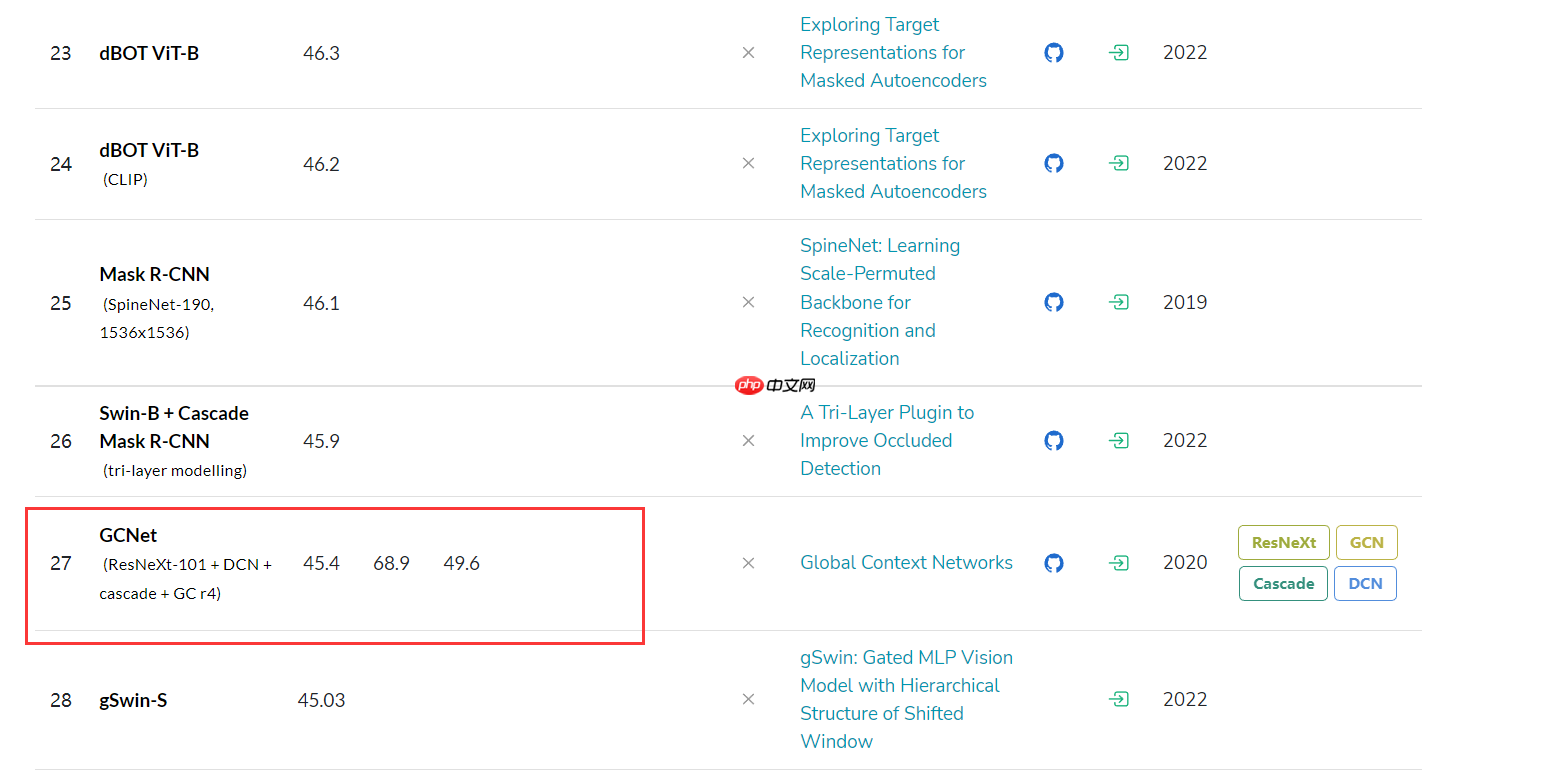
在paperwithcode网站上,可看出gcnet在Instance Segmentation on COCO test-dev上mask_AP高达45.4,算是比较不错的算法
3.2、浅谈一下其他算法
3.2.1、KNet:
KNet 是一种基于卷积神经网络(CNN)的语义分割算法,它采用了 U-Net 架构,并增加了 skip connections 和 deep supervision 等创新技术。该模型接收一张图像作为输入,输出是每个像素的类别标签。在训练过程中,KNet 通常使用交叉熵损失函数和随机梯度下降法优化算法进行学习。
优点:KNet展现出了极高的准确度,在处理微小物体和复杂的环境背景上效果显著。它的设计理念简洁易懂,易于理解与实际操作。KNet广泛应用于图像分割任务,涵盖医学图像分割及自然图像分割等多个领域。
缺陷分析:KNet由于复杂的计算结构,对计算资源的需求较大,并且其对于输入图像的尺寸与分辨率有一定依赖性,需要进行特定的预处理(如图像尺度归一化)。此外,在解决像遮挡、遮蔽和形状不规则等问题时,可能会产生一定程度的误差。
3.2.2、MaskFormer:
MaskFormer 是一种基于 Transformer 的语义分割算法,它使用自注意力机制捕捉长距离依赖关系,并将它们与局部特征结合在一起。MaskFormer 的输入是一张图像,输出是该图像中每个像素的掩码。其训练过程通常采用二进制交叉熵损失函数和 Adam 优化算法。
优点:MaskFormer 具有极高的准确性,并在处理遮挡、遮蔽和不规则形状等问题时表现卓越。其训练速度非常快,在大规模数据集上也能轻松胜任。 MaskFormer 的掩码输出适用于多种分割任务,如实例分割和语义分割等。
优点:在处理大规模图片时,MaskFormer表现出色。缺点:其计算量较大,需要更强大的硬件支持;对图像尺寸有较高的要求,需进行特定的预处理步骤。
3.2.3、UperNet:
UperNet 是一种基于Encoder-Decoder架构的语义分割技术,它通过结合多尺度特征来提升分割精度。输入为一张图像,输出则是该图像中每个像素的类别标签。在训练过程中,通常采用交叉熵损失函数和随机梯度下降算法。
优点:UperNet 拥有极高的准确性,在应对遮挡和不规则形状等问题时表现优异。它的计算效率不高,但速度快。此外,UperNet 的结构非常灵活,用户可以轻松调整层的数量和通道来适应不同的应用需求。
优点:UperNet 在处理大量遮挡和遮蔽等问题时表现出色,具有很高的准确性和稳定性;其特征融合过程不产生信息损失,确保了分割的准确性;由于多尺度特征融合,它无需对输入图像进行多次下采样和上采样,从而保持了分辨率和精度。
综上所述,KNet、MaskFormer和UperNet在图像分割任务中有广泛的应用,并且这些算法各具特色。每个算法都有其优势与劣势,因此在决定使用何种方法时,需要根据具体的场景和需求来选择,这样才能达到最佳的分割效果和性能。
3.2.4、逐像素分割和逐 mask分割各自优缺点
逐像素分割和逐 mask 分割是两种常用的图像分割方法。
逐像素分割,又称全像素分割,是指每个图像上的每一个像素被分配到不同的目标类别中。这种技术的优点是能够生成极精确的分割结果,可以详细展示目标物体的形状与轮廓细节,特别适用于尺寸小且形态复杂的目标识别场景。然而,逐像素分割也有其缺点:计算量较大,需要处理海量的像素点;同时容易受到噪声的影响,对这些干扰因素敏感,因此在实际应用中通常会进行预处理如去噪等步骤以提高准确率。
逐mask分割,又称实例分割,是一种将图像中每个目标实例分配到不同的目标类别的技术,使得同一目标的所有像素点归为一个类别,从而获得实例级别的分割结果。逐mask分割的优点在于能够提供准确的实例级分割结果,对于尺寸较大且形状简单的目标有良好的表现,并且由于没有依赖于背景信息的规则化处理,具有较强的抗噪声能力。然而,这种方法也存在一些局限性:首先,它无法清晰地区分同一类别的不同实例,使得这些实例在识别时可能被混淆;其次,它也无法捕捉到目标细节的信息,对于尺寸小、形状复杂的对象则表现不佳。虽然逐mask分割方法有很多优点,但在实际应用中也有其限制。为了克服这些缺点,可以尝试结合其他更复杂的方法或算法来提高模型的性能和实用性。例如,可以通过引入更多的监督信息(如实例级别的边界框)或者使用更先进的图像处理技术(如目标检测与识别技术)来进行改进。总之,逐mask分割是图像处理领域中的一个关键工具,但在应用中需要权衡其优势与局限性,并通过不断的技术创新来提高其实际效果。
总之,逐像素分割和逐mask分割各有优势与劣势。因此,在选择分割方法时需综合考量目标大小、形状、数量及噪音水平,并结合具体应用需求,比如实例级分割的要求。
3.2.5、总体而言
选择适合特定应用场景的分割算法非常重要。为了确保高准确性且有足够的计算资源,可以考虑使用 KNet 和 MaskFormer。然而,如果你倾向于在时间和计算资源上更加高效,那么可以选择 UperNet。此外,如果图像中包含大量遮挡、遮蔽或不规则形状,则 MaskFormer 可能是更好的选择。
在逐像素分割和逐 mask 分割方面,逐像素分割更为精准但计算复杂度较高;而逐 mask 分割能更精细地区分不同实例但存在重叠风险,并需额外生成掩码,因而速度相对较慢。
综上所述,应根据具体的应用场景和需求来选择适合的分割算法和分割方式。
3.3、开始训练
In []
在Aistudio环境设置中,使用以下命令启动并运行PaddleSeg训练任务: ``` cd /home/aistudio/work/PaddleSeg !python train.py \ --config configs/gcnet/gcnet_resnetosvocug_.yml \ --do_eval \ --use_vdl \ --save_interval \ --save_dir output1 ``` 其中`cd /home/aistudio/work/PaddleSeg`用于切换到PaddleSeg文件夹,确保你已经在正确的工作目录下。运行命令时,请确保你的Python环境已经安装,并且所有依赖库都已正确配置。启动后,系统将根据配置文件进行训练,并在指定的间隔周期内保存模型状态或评估效果。如果启用了Vdl日志功能,还可以通过指定路径访问和可视化训练过程。
3.4、数据模型可视化
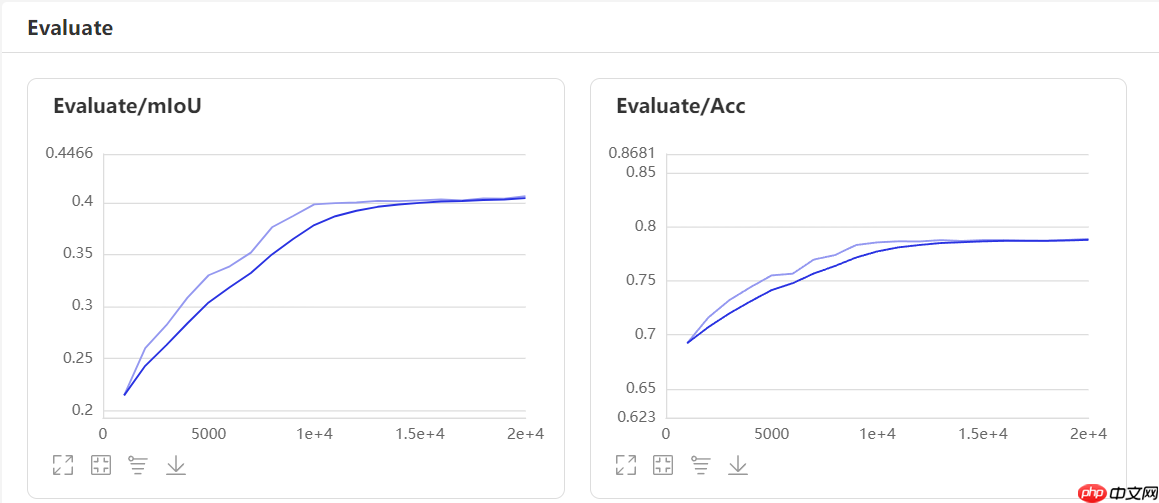
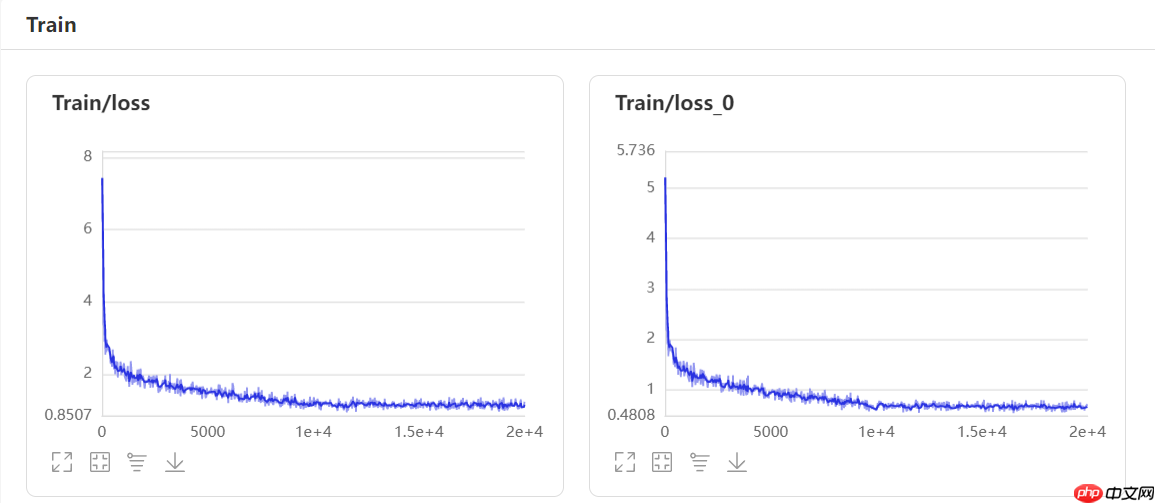
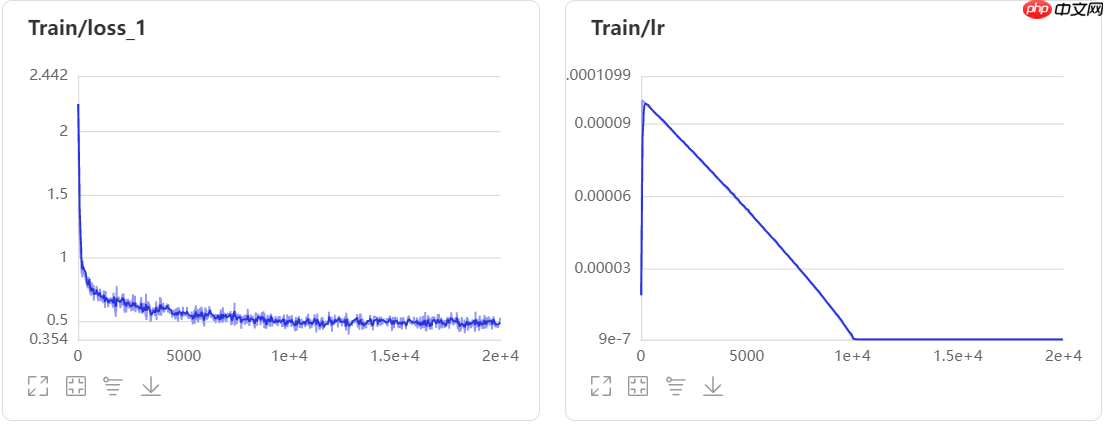
3.5、补充一下Upernet模型
In []
%cd /home/aistudio/work/PaddleSeg !python train.py \ --config configs/upernet/upernet_resnet101_os8_cityscapes_512x1024_40k.yml \ --do_eval \ --use_vdl \ --save_interval 1000 \ --save_dir output2 \ # --resume_model output2/iter_8000 \ # --resume_model 恢复训练# 配置文件位置为/home/aistudio/work/PaddleSeg/configs/upernet/upernet_resnet101_os8_cityscapes_512x1024_40k.yml登录后复制
Upernet训练过程可视化
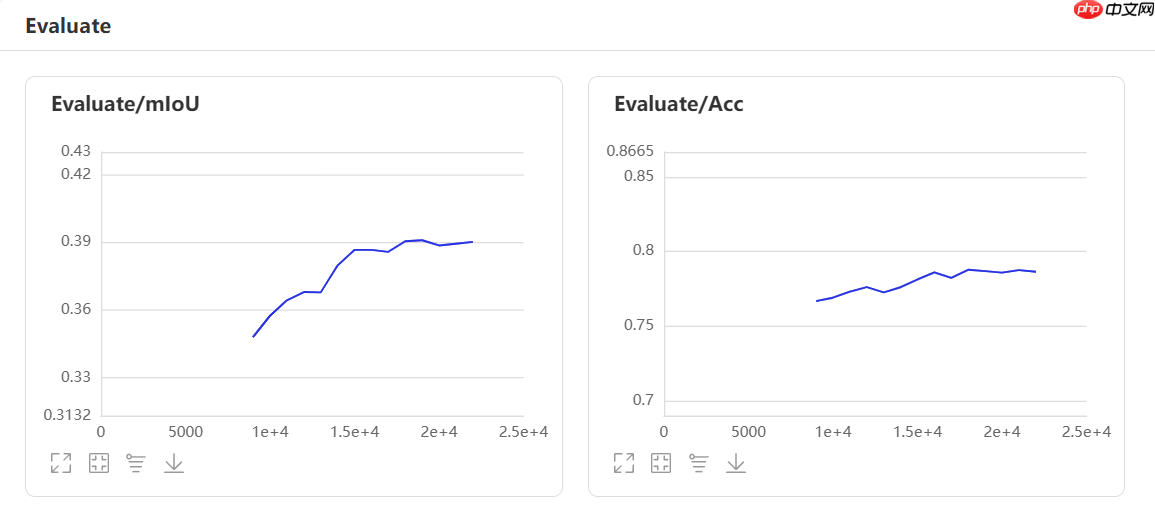
四、模型验证
笔者在/home/aistudio/work/PaddleSeg/output1/best_model下准备了GCNet的best_model,直接运行以下代码块即可查看效果 In [2]
%cd /home/aistudio/work/PaddleSeg !python val.py \ --config configs/gcnet/gcnet_resnet50_os8_voc12aug_512x512_40k.yml \ --model_path output1/best_model/model.pdparams \登录后复制
/home/aistudio/work/PaddleSeg 2023-03-24 08:26:55 [INFO] ---------------Config Information--------------- batch_size: 13 iters: 20000 loss: coef: - 1 - 0.4 types: - type: CrossEntropyLoss lr_scheduler: decay_steps: 10000 end_lr: 1.0e-06 learning_rate: 0.0001 power: 0.9 type: PolynomialDecay warmup_iters: 50 warmup_start_lr: 1.6e-06 model: align_corners: false backbone: output_stride: 8 pretrained: https://bj.bcebos.com/paddleseg/dygraph/resnet50_vd_ssld_v2.tar.gz type: ResNet50_vd enable_auxiliary_loss: true gc_channels: 512 pretrained: null ratio: 0.25 type: GCNet optimizer: beta1: 0.9 beta2: 0.999 type: AdamW weight_decay: 0.05 train_dataset: dataset_root: /home/aistudio/work/dataset/ADEChallengeData2016/ mode: train transforms: - max_scale_factor: 2.0 min_scale_factor: 0.5 scale_step_size: 0.25 type: ResizeStepScaling - crop_size: - 512 - 512 type: RandomPaddingCrop - type: RandomHorizontalFlip - brightness_range: 0.4 contrast_range: 0.4 saturation_range: 0.4 type: RandomDistort - type: Normalize type: ADE20K val_dataset: dataset_root: /home/aistudio/work/dataset/ADEChallengeData2016/ mode: val transforms: - type: Normalize type: ADE20K ------------------------------------------------ W0324 08:26:55.128404 3109 gpu_resources.cc:61] Please NOTE: device: 0, GPU Compute Capability: 7.0, Driver API Version: 11.2, Runtime API Version: 11.2 W0324 08:26:55.128458 3109 gpu_resources.cc:91] device: 0, cuDNN Version: 8.2. 2023-03-24 08:26:56 [INFO] Loading pretrained model from https://bj.bcebos.com/paddleseg/dygraph/resnet50_vd_ssld_v2.tar.gz Connecting to https://bj.bcebos.com/paddleseg/dygraph/resnet50_vd_ssld_v2.tar.gz Downloading resnet50_vd_ssld_v2.tar.gz [==================================================] 100.00% Uncompress resnet50_vd_ssld_v2.tar.gz [==================================================] 100.00% 2023-03-24 08:27:06 [INFO] There are 275/275 variables loaded into ResNet_vd. 2023-03-24 08:27:06 [INFO] Loading pretrained model from output1/best_model/model.pdparams 2023-03-24 08:27:06 [INFO] There are 311/311 variables loaded into GCNet. 2023-03-24 08:27:06 [INFO] Loaded trained params of model successfully 2023-03-24 08:27:06 [INFO] Start evaluating (total_samples: 2000, total_iters: 2000)... 2000/2000 [==============================] - 150s 75ms/step - batch_cost: 0.0749 - reader cost: 2.2674e-04 2023-03-24 08:29:37 [INFO] [EVAL] #Images: 2000 mIoU: 0.4060 Acc: 0.7891 Kappa: 0.7733 Dice: 0.5450 2023-03-24 08:29:37 [INFO] [EVAL] Class IoU: [0.7124 0.8008 0.9313 0.7649 0.7004 0.7802 0.7785 0.8228 0.5516 0.6548 0.5171 0.5712 0.7614 0.3339 0.3057 0.4794 0.5427 0.4586 0.6691 0.4856 0.8022 0.4848 0.598 0.5627 0.3497 0.4863 0.4897 0.4337 0.4701 0.2799 0.347 0.5287 0.3518 0.3859 0.42 0.3769 0.5323 0.6636 0.2801 0.4832 0.1924 0.1725 0.4099 0.3104 0.3519 0.2163 0.3782 0.6042 0.539 0.6257 0.5381 0.401 0.1217 0.2473 0.6241 0.4786 0.8794 0.458 0.4401 0.2717 0.1967 0.5515 0.2755 0.2419 0.4676 0.758 0.2995 0.3691 0.05 0.3994 0.4922 0.6181 0.4712 0.2761 0.5462 0.3593 0.4183 0.4103 0.5348 0.3811 0.6988 0.5173 0.3753 0.1949 0.3953 0.5977 0.171 0.1695 0.2836 0.6271 0.5258 0.0745 0.3111 0.1573 0.0004 0.0924 0.2422 0.3383 0.19 0.4618 0.0716 0.0486 0.3279 0.6406 0.2951 0.5686 0.1721 0.6494 0.2546 0.4074 0.3229 0.1346 0.2477 0.5765 0.8193 0.1123 0.601 0.7063 0.2151 0.3593 0.5408 0.0423 0.2745 0.1847 0.4372 0.2888 0.512 0.4712 0.0009 0.4836 0.6393 0.0429 0.3087 0.3261 0.1744 0.2856 0.2329 0.0178 0.3722 0.4944 0.4709 0.0724 0.444 0.021 0.4145 0.0017 0.4981 0.1145 0.1682 0.2814] 2023-03-24 08:29:37 [INFO] [EVAL] Class Precision: [0.8119 0.8695 0.962 0.8547 0.7814 0.8793 0.8997 0.8753 0.7011 0.7864 0.7353 0.6727 0.8435 0.5302 0.6102 0.6638 0.7082 0.7214 0.7994 0.6683 0.8769 0.6835 0.7093 0.6884 0.5274 0.6138 0.5585 0.6761 0.7636 0.393 0.5105 0.6331 0.5877 0.5448 0.5405 0.4941 0.7326 0.7843 0.4651 0.6829 0.359 0.4159 0.6445 0.567 0.5198 0.5016 0.5896 0.7959 0.6443 0.7543 0.6547 0.444 0.3063 0.599 0.6497 0.5739 0.9083 0.7014 0.5525 0.4622 0.3538 0.684 0.4142 0.688 0.5741 0.8462 0.5175 0.5607 0.1598 0.6991 0.6164 0.7631 0.6411 0.3225 0.7192 0.4976 0.5331 0.6106 0.7578 0.542 0.7403 0.7045 0.7159 0.3659 0.753 0.7415 0.4658 0.443 0.6463 0.753 0.7322 0.1231 0.513 0.4166 0.0036 0.3219 0.5174 0.5526 0.4577 0.6989 0.3567 0.0755 0.6647 0.7321 0.721 0.6855 0.3575 0.9111 0.4424 0.5729 0.6351 0.1438 0.49 0.629 0.8332 0.436 0.746 0.7556 0.3095 0.4968 0.7359 0.3707 0.7468 0.6528 0.8193 0.6748 0.8287 0.6061 0.0664 0.645 0.7521 0.4227 0.5671 0.7565 0.6982 0.4636 0.4544 0.1138 0.5872 0.6711 0.6449 0.0955 0.6682 0.2432 0.6712 0.0112 0.8014 0.5777 0.4641 0.6835] 2023-03-24 08:29:37 [INFO] [EVAL] Class Recall: [0.8531 0.9103 0.9668 0.8792 0.871 0.8739 0.8525 0.9321 0.7212 0.7964 0.6354 0.791 0.8867 0.4742 0.38 0.6331 0.6991 0.5574 0.804 0.6397 0.904 0.6252 0.7922 0.7549 0.5092 0.7007 0.7988 0.5474 0.5502 0.493 0.52 0.7623 0.4671 0.5695 0.6534 0.6139 0.6606 0.8117 0.4132 0.623 0.2931 0.2276 0.5298 0.4069 0.5214 0.2755 0.5134 0.715 0.7672 0.7858 0.7512 0.8054 0.1679 0.2964 0.9406 0.7424 0.9651 0.569 0.684 0.3973 0.3069 0.74 0.4515 0.2717 0.7159 0.8791 0.4155 0.5193 0.0678 0.4824 0.7096 0.7648 0.6399 0.6571 0.6943 0.5639 0.66 0.5558 0.6451 0.5622 0.9258 0.6606 0.441 0.2942 0.4542 0.755 0.2127 0.2154 0.3357 0.7894 0.6509 0.1586 0.4415 0.2017 0.0004 0.1147 0.3129 0.4659 0.2452 0.5765 0.0822 0.1199 0.3929 0.8367 0.3332 0.7692 0.2492 0.6933 0.375 0.5852 0.3965 0.6772 0.3337 0.8734 0.98 0.1314 0.7557 0.9155 0.4136 0.5649 0.6711 0.0456 0.3027 0.2048 0.4839 0.3355 0.5727 0.6792 0.0009 0.659 0.81 0.0456 0.4039 0.3644 0.1886 0.4266 0.3233 0.0207 0.5042 0.6526 0.6357 0.2303 0.5697 0.0225 0.5201 0.0019 0.5683 0.125 0.2087 0.3236]登录后复制
笔者在/home/aistudio/work/PaddleSeg/output2/best_model下准备了Upernet的best_model,直接运行以下代码块即可查看效果 In [3]
%cd /home/aistudio/work/PaddleSeg !python val.py \ --config configs/upernet/upernet_resnet101_os8_cityscapes_512x1024_40k.yml \ --model_path output2/best_model/model.pdparams \登录后复制
/home/aistudio/work/PaddleSeg 2023-03-24 08:53:26 [INFO] ---------------Config Information--------------- batch_size: 8 iters: 40000 loss: coef: - 1 - 0.4 types: - type: CrossEntropyLoss lr_scheduler: decay_steps: 20000 end_lr: 1.0e-06 learning_rate: 0.001 power: 1.5 type: PolynomialDecay warmup_iters: 150 warmup_start_lr: 1.6e-06 model: backbone: output_stride: 8 pretrained: https://bj.bcebos.com/paddleseg/dygraph/resnet101_vd_ssld.tar.gz type: ResNet101_vd backbone_indices: - 0 - 1 - 2 - 3 channels: 512 dropout_prob: 0.1 enable_auxiliary_loss: true type: UPerNet optimizer: type: sgd weight_decay: 0.0005 train_dataset: dataset_root: /home/aistudio/work/dataset/ADEChallengeData2016/ mode: train transforms: - max_scale_factor: 2.0 min_scale_factor: 0.5 scale_step_size: 0.25 type: ResizeStepScaling - crop_size: - 512 - 512 type: RandomPaddingCrop - type: RandomHorizontalFlip - brightness_range: 0.4 contrast_range: 0.4 saturation_range: 0.4 type: RandomDistort - type: Normalize type: ADE20K val_dataset: dataset_root: /home/aistudio/work/dataset/ADEChallengeData2016/ mode: val transforms: - type: Normalize type: ADE20K ------------------------------------------------ W0324 08:53:26.108537 7681 gpu_resources.cc:61] Please NOTE: device: 0, GPU Compute Capability: 7.0, Driver API Version: 11.2, Runtime API Version: 11.2 W0324 08:53:26.108594 7681 gpu_resources.cc:91] device: 0, cuDNN Version: 8.2. 2023-03-24 08:53:27 [INFO] Loading pretrained model from https://bj.bcebos.com/paddleseg/dygraph/resnet101_vd_ssld.tar.gz 2023-03-24 08:53:29 [INFO] There are 530/530 variables loaded into ResNet_vd. 2023-03-24 08:53:29 [INFO] Loading pretrained model from output2/best_model/model.pdparams 2023-03-24 08:53:30 [INFO] There are 616/616 variables loaded into UPerNet. 2023-03-24 08:53:30 [INFO] Loaded trained params of model successfully 2023-03-24 08:53:30 [INFO] Start evaluating (total_samples: 2000, total_iters: 2000)... 2000/2000 [==============================] - 230s 115ms/step - batch_cost: 0.1149 - reader cost: 2.6253e-04 2023-03-24 08:57:20 [INFO] [EVAL] #Images: 2000 mIoU: 0.3909 Acc: 0.7868 Kappa: 0.7713 Dice: 0.5292 2023-03-24 08:57:20 [INFO] [EVAL] Class IoU: [0.7115 0.8011 0.9314 0.7647 0.7042 0.787 0.8049 0.84 0.5649 0.6462 0.5362 0.5995 0.7441 0.3094 0.3554 0.4754 0.536 0.4481 0.6626 0.4777 0.8098 0.4829 0.6057 0.5982 0.3838 0.4725 0.5459 0.496 0.491 0.2577 0.356 0.533 0.3685 0.3815 0.4109 0.3827 0.5311 0.6146 0.3125 0.4607 0.2319 0.1872 0.4051 0.3083 0.3786 0.3747 0.2756 0.5684 0.5776 0.5924 0.5052 0.3146 0.1775 0.1849 0.6592 0.4048 0.8408 0.4871 0.4102 0.2576 0.118 0.4577 0.3204 0.2345 0.4711 0.7338 0.2616 0.4106 0.0548 0.3417 0.4774 0.5949 0.4258 0.2156 0.4975 0.3868 0.39 0.3472 0.5401 0.3453 0.5822 0.4809 0.3615 0.2809 0.2508 0.5794 0.1629 0.1485 0.2743 0.6273 0.4158 0.0254 0.1913 0.0738 0.0096 0.0065 0.2471 0.3797 0.2024 0.4278 0.1038 0.0625 0.2214 0.643 0.4732 0.3105 0.1562 0.516 0.2314 0.3265 0.2965 0.0689 0.2294 0.5552 0.5121 0.0194 0.6406 0.6248 0.1877 0.3104 0.5239 0.0125 0.2889 0.211 0.5088 0.2775 0.5669 0.4562 0.0099 0.4972 0.5025 0.0066 0.3107 0.3572 0.1159 0.2616 0.2058 0.0123 0.343 0.4589 0.3581 0.0646 0.4363 0.2756 0.374 0. 0.4782 0.087 0.1422 0.3191] 2023-03-24 08:57:21 [INFO] [EVAL] Class Precision: [0.8287 0.8841 0.9687 0.8747 0.7825 0.8856 0.9059 0.8874 0.7003 0.801 0.7608 0.7409 0.8732 0.5617 0.6384 0.6547 0.7048 0.7229 0.8222 0.6973 0.883 0.6961 0.7002 0.6883 0.531 0.5755 0.6419 0.6524 0.7158 0.3307 0.5137 0.5957 0.5923 0.5299 0.4938 0.4602 0.7291 0.6983 0.5043 0.7226 0.3873 0.3407 0.5983 0.5291 0.6176 0.611 0.4069 0.8419 0.6112 0.645 0.5909 0.336 0.3525 0.6151 0.6872 0.4666 0.8622 0.7264 0.4477 0.3868 0.171 0.4977 0.4181 0.6474 0.5378 0.807 0.3646 0.5995 0.1186 0.5065 0.6388 0.7217 0.5087 0.2645 0.6051 0.4658 0.4694 0.6118 0.6464 0.6077 0.6045 0.6908 0.7662 0.536 0.4042 0.7233 0.5561 0.361 0.4804 0.7987 0.5181 0.0578 0.2771 0.3427 0.1093 0.0297 0.3534 0.6737 0.5066 0.5739 0.3667 0.0786 0.5355 0.6774 0.8164 0.3551 0.4044 0.5904 0.4412 0.3715 0.6888 0.0715 0.4757 0.6028 0.5123 0.2882 0.7996 0.636 0.2419 0.3764 0.6865 0.3466 0.4599 0.6474 0.7609 0.7099 0.8262 0.5613 0.0392 0.7182 0.5333 0.0976 0.464 0.675 0.6291 0.4505 0.3991 0.0596 0.7079 0.63 0.4212 0.1156 0.6099 0.5317 0.7055 0.0002 0.7177 0.6002 0.7423 0.7913] 2023-03-24 08:57:21 [INFO] [EVAL] Class Recall: [0.8341 0.8951 0.9604 0.8587 0.8757 0.876 0.8783 0.9402 0.745 0.7698 0.6449 0.7585 0.8343 0.408 0.445 0.6346 0.6911 0.5411 0.7734 0.6026 0.9071 0.6118 0.8178 0.8204 0.5808 0.7254 0.785 0.6742 0.6099 0.5387 0.5371 0.835 0.4938 0.5767 0.71 0.6946 0.6616 0.8369 0.4509 0.5597 0.3663 0.2936 0.5564 0.4249 0.4945 0.4921 0.4605 0.6363 0.9129 0.8789 0.7769 0.8319 0.2634 0.209 0.9419 0.7533 0.9713 0.5966 0.8307 0.4353 0.2759 0.8507 0.5785 0.2688 0.7914 0.89 0.481 0.5658 0.0925 0.5122 0.6539 0.772 0.7231 0.5384 0.7368 0.6954 0.6975 0.4454 0.7666 0.4444 0.9404 0.6128 0.4063 0.3712 0.3978 0.7444 0.1872 0.2014 0.39 0.745 0.678 0.0432 0.382 0.086 0.0104 0.0082 0.451 0.4653 0.2521 0.6268 0.1264 0.2341 0.274 0.9267 0.5296 0.7119 0.2028 0.8036 0.3274 0.7295 0.3424 0.6512 0.3069 0.8755 0.9995 0.0204 0.7632 0.9726 0.4559 0.639 0.6886 0.0128 0.4371 0.2384 0.6056 0.313 0.6437 0.7089 0.0131 0.6177 0.8969 0.007 0.4847 0.4314 0.1244 0.3841 0.2983 0.0152 0.3996 0.6282 0.705 0.1277 0.6051 0.364 0.4432 0. 0.5889 0.0924 0.1496 0.3485]登录后复制
五、模型预测
笔者在/home/aistudio/work/PaddleSeg/output1/best_model下准备了GCNet的best_model,直接运行以下代码块即可查看ade20k数据集中测试集的效果 In []
请在您的电脑上运行以下命令:cd /home/aistudio/work/PaddleSeg然后执行此命令以进行预测: python predict.py \ --config configs/gcnet/gcnet_resnetosvocug_.yml \ --model_path outputbest_model/model.pdparams \ --image_path /home/aistudio/work/dataset/ADEChallengeDataimages/testing \ --save_dir outputresult注意,您需要确保具有执行这些命令所需的权限。成功运行后,预测结果将被保存在路径/home/aistudio/work/PaddleSeg/outputresult中。
笔者在/home/aistudio/work/PaddleSeg/output2/best_model下准备了Upernet的best_model,直接运行以下代码块即可查看ade20k数据集中测试集的效果 In []
请在本地服务器上运行以下命令生成PaddleSeg模型的预测结果:```bash cd /home/aistudio/work/PaddleSeg/ !python predict.py \ --config configs/upernet/upernet_resnetoscityscapes_.yml \ --model_path output/best_model/model.pdparams \ --image_path /home/aistudio/work/dataset/ADEChallengeDataimages/testing \ --save_dir output/result ```注意:请确保您已安装并配置了所需的Python环境,同时将`output和`result`替换为实际的路径。如果您没有本地服务器,请通过SSH连接到您的机器执行此命令。
六、对比与总结
模型1 backbone 验证集miou 验证耗时 模型文件大小 GCnet resnet50_vd 0.4060 150s 75ms/step 190MB 模型2 backbone 验证集miou 验证耗时 模型文件大小 Upernet ResNet101_vd 0.3909 230s 115ms/step 390.5MB
通过对比可以看出:GCnet优于Upernet
总结:
在这个数据集上训练模型并不难,但是获得良好的mIoU结果却颇具挑战。这需要精心挑选算法和参数配置,确保模型性能最佳。
除此之外,我还研究过Setr_mla_large算法。该算法使用了ViT_large_patch为其backbone(配置文件路径为/home/aistudio/work/PaddleSeg/configs/setr/setr_mla_large_cityscapes_.yml)。尽管可以预见其效果将优于GCNet,但训练时验证过程却异常缓慢,估计需要至少半小时。然而,由于这个问题是ViT系列模型的普遍问题,我最终选择了放弃研究。
在这个经验分享中,我主要提到了配置文件方面的一个不满意之处学习率策略、优化器和损失函数的选择。虽然GitHub中的paddleseg参考文档相对较少,但是一些地方确实可以提供帮助。我在处理自适应学习策略时遇到了一些挑战,但幸运的是通过查看源码找到了解决方案。对于那些希望在配置文件中为自适应学习策略传递验证集损失的人来说,了解并使用paddle框架的API文档是非常重要的,它将极大地助你调参。
以上就是【AI达人特训营第三期】:PaddleSeg助力自动驾驶场景分割的详细内容,更多请关注其它相关文章!
热门推荐
-
【AI达人特训营第三期】:PaddleSeg助力自动驾驶场景分割本文介绍使用PaddleSeg工具处理基于ADE数据集场景解析的过程。首先,解压相关软件及数据集,并加载并预处理它们
-
永劫无间无法进入大厅 老司机教你几招,秒变排队达人铁友们,不要急着吐槽“永劫无间无法进入大厅”的困扰了!别忘了喝杯热茶暖暖身子,我们坐下来好好聊聊。今天,我打算把这事儿说透彻,绝对干货满满,让你看得懂、记得住
-
 汉字达人爱心宠物店怎么过_汉字达人爱心宠物店将宠物店的价格砍到最低通关攻略汉字达人爱心宠物店将宠物店的价格砍到最低通关攻略:在汉字达人游戏很多关卡还是挺多的,当然这些关卡玩起来也是非常有意思的。小编整理了爱心宠物店关卡如何玩呢?下面一起来看看相关的信息。
汉字达人爱心宠物店怎么过_汉字达人爱心宠物店将宠物店的价格砍到最低通关攻略汉字达人爱心宠物店将宠物店的价格砍到最低通关攻略:在汉字达人游戏很多关卡还是挺多的,当然这些关卡玩起来也是非常有意思的。小编整理了爱心宠物店关卡如何玩呢?下面一起来看看相关的信息。 -
 汉字达人独居女孩找出十个细思极恐的地方怎么过汉字达人独居女孩找出十个细思极恐的地方怎么过:在汉字达人游戏中挑战关卡还是挺多的,当然这些关卡玩起来也是相当有特色的。小编整理了汉字达人独居女孩关卡玩法详解,下面一起来看看相关的信息。
汉字达人独居女孩找出十个细思极恐的地方怎么过汉字达人独居女孩找出十个细思极恐的地方怎么过:在汉字达人游戏中挑战关卡还是挺多的,当然这些关卡玩起来也是相当有特色的。小编整理了汉字达人独居女孩关卡玩法详解,下面一起来看看相关的信息。 -
 上半年中国新势力汽车销售金额排名:小米410亿居第三近日,有汽车媒体整理并发布了225年上半年中国新势力车企整车销售金额排行榜,具体情况如下:第一名:理想汽车,约64亿元;理想汽车第二名:问界汽车,约55亿元;问界
上半年中国新势力汽车销售金额排名:小米410亿居第三近日,有汽车媒体整理并发布了225年上半年中国新势力车企整车销售金额排行榜,具体情况如下:第一名:理想汽车,约64亿元;理想汽车第二名:问界汽车,约55亿元;问界 -
 青年大学习第十一季第三期答案是什么-第十一季第三期所有最新答案大全的青年大学习正在进行中,主题为“星星之火可以燎原”。这期节目里涉及的列强与军阀相关信息很多,请仔细复习以备不时之需
青年大学习第十一季第三期答案是什么-第十一季第三期所有最新答案大全的青年大学习正在进行中,主题为“星星之火可以燎原”。这期节目里涉及的列强与军阀相关信息很多,请仔细复习以备不时之需 -
 西乌旗第三届草原99号公路音乐节正式开票近年来,内蒙古自治区的锡林郭勒盟西乌珠穆沁旗(简称“西乌旗”)积极贯彻现代文旅融合发展战略,持续致力于“公路”的旅游品牌建设
西乌旗第三届草原99号公路音乐节正式开票近年来,内蒙古自治区的锡林郭勒盟西乌珠穆沁旗(简称“西乌旗”)积极贯彻现代文旅融合发展战略,持续致力于“公路”的旅游品牌建设 -
黄沙奇遇《第五人格》第三十八赛季精华2即将上线冒险启程,惊喜降临。在即将开启的第五人格第三十七八赛季中,策略准备已经就绪!幽静之处,微风吹过芦苇,见证着永恒不变的故事生命循环、永生之歌在天籁间回响
-
 用豆包AI实现自动化测试脚本?AI助力高效代码调试豆包AI可以辅助实现自动化测试脚本的编写,但并不能完全替代人工。以下是具体应用:通过输入功能点或接口文档自动生成基础测试脚本,例如登录接口的边界测试用例
用豆包AI实现自动化测试脚本?AI助力高效代码调试豆包AI可以辅助实现自动化测试脚本的编写,但并不能完全替代人工。以下是具体应用:通过输入功能点或接口文档自动生成基础测试脚本,例如登录接口的边界测试用例 -
 助力教育数智化转型 华为擎云亮相第五届四川教育博览会随着教育强国战略的实施,数字科技正成为推动教育创新的关键力量。在这一背景下,加快智慧校园的标准化建设和推广智能教学设备成为了提升教育竞争力的重要途径
助力教育数智化转型 华为擎云亮相第五届四川教育博览会随着教育强国战略的实施,数字科技正成为推动教育创新的关键力量。在这一背景下,加快智慧校园的标准化建设和推广智能教学设备成为了提升教育竞争力的重要途径 -
 PS5 Pro推动视觉保真度 助力《异形》新作画面提升异形:外星入侵的第一部分已在推出PlayStationVRMetaQuestPCVR硬件,而游戏的非VR版本“进化版”将于今年在PSPC平台上市
PS5 Pro推动视觉保真度 助力《异形》新作画面提升异形:外星入侵的第一部分已在推出PlayStationVRMetaQuestPCVR硬件,而游戏的非VR版本“进化版”将于今年在PSPC平台上市 -
第五人格IVL Gr_Jin惊艳发挥三局四抓 助力队伍获取比赛胜利随着第六个比赛日的到来,今日比赛开始了,在此次比赛中,G战队凭借出色的发挥,以的成绩(战胜了MRC,赢得了胜利
-
 AI Overviews是什么 有哪些场景适合使用AI Overviews功能AIOverviews是一项由搜索引擎尝试推出的实验性功能,旨在通过先进的人工智能技术,对用户搜索结果进行智能化的概括和总结
AI Overviews是什么 有哪些场景适合使用AI Overviews功能AIOverviews是一项由搜索引擎尝试推出的实验性功能,旨在通过先进的人工智能技术,对用户搜索结果进行智能化的概括和总结 -
 远光84撕裂地场景有什么用途 远光84手游场景相关情报分享在这片名为“撕裂地”的广阔战场上,莉莉丝旗下的英雄射击游戏远光现了无尽的策略与勇气。这张地图是连通不同区域的关键,穿山隧道贯穿其间,内部昏暗,成为重要的交通要道和
远光84撕裂地场景有什么用途 远光84手游场景相关情报分享在这片名为“撕裂地”的广阔战场上,莉莉丝旗下的英雄射击游戏远光现了无尽的策略与勇气。这张地图是连通不同区域的关键,穿山隧道贯穿其间,内部昏暗,成为重要的交通要道和 -
 部落冲突天宫场景卡怎么使用 使用场景有什么在部落冲突这款广受欢迎的策略游戏中,场景卡是玩家改变游戏环境、获取特定效果的重要工具。作为一款深受喜爱的游戏道具,天宫场景卡以其独特的装饰性和功能受到了许多玩家的
部落冲突天宫场景卡怎么使用 使用场景有什么在部落冲突这款广受欢迎的策略游戏中,场景卡是玩家改变游戏环境、获取特定效果的重要工具。作为一款深受喜爱的游戏道具,天宫场景卡以其独特的装饰性和功能受到了许多玩家的 -
王者荣耀世界地图有什么区域 全地图场景特色介绍王者荣耀的世界是基于开放世界风格的RPG游戏。它拥有丰富多样的地图与场景,每个地方都有其独特魅力和游戏规则